Les actualités du Mercredi 02 octobre 2024 dans les métiers du web - Marmits.com - Reims
 Rencontrée au One to One expérience client, Frédérique Cuvelier, directrice du CRM omnicanal chez Carrefour, partage la stratégie du groupe pour atteindre les 30% de clients omnicanaux.
Rencontrée au One to One expérience client, Frédérique Cuvelier, directrice du CRM omnicanal chez Carrefour, partage la stratégie du groupe pour atteindre les 30% de clients omnicanaux.
Rencontrée au One to One expérience client, Frédérique Cuvelier, directrice du CRM omnicanal chez Carrefour, partage la stratégie du groupe pour atteindre les 30% de clients omnicanaux.
 Des règles internes controversées, touchant à la confidentialité et aux accords de non-divulgation, sont au centre d'une plainte déposée contre le géant technologique. Les autorités demandent leur révision pour respecter les droits des salariés.
Des règles internes controversées, touchant à la confidentialité et aux accords de non-divulgation, sont au centre d'une plainte déposée contre le géant technologique. Les autorités demandent leur révision pour respecter les droits des salariés.
 Les deux tiers de l'effort doivent se traduire par des économies de dépenses, le dernier tiers par des mesures fiscales.
Les deux tiers de l'effort doivent se traduire par des économies de dépenses, le dernier tiers par des mesures fiscales.
Hey everyone ð, this week I dive into design system primitive components. They are extremely beneficial to help adopters of your system rapidly iterate experiences using design tokens. Excited to chat about this topic and would love to hear what you all think of it.
 La réindustrialisation européenne cherche à renforcer sa souveraineté technologique, notamment via l'European Chips Act, en misant sur l'innovation et l'autonomie industrielle.
La réindustrialisation européenne cherche à renforcer sa souveraineté technologique, notamment via l'European Chips Act, en misant sur l'innovation et l'autonomie industrielle.
 La gestion des projets d'IA reflète souvent la théorie de l'iceberg, les tâches visibles ne représentant qu'une petite fraction des complexités en jeu.
La gestion des projets d'IA reflète souvent la théorie de l'iceberg, les tâches visibles ne représentant qu'une petite fraction des complexités en jeu.
 La Ligue de Football Professionnel a dernièrement dévoilé les nouvelles briques de son écosystème digital en mettant l'accent sur la personnalisation des contenus et la gamification.
La Ligue de Football Professionnel a dernièrement dévoilé les nouvelles briques de son écosystème digital en mettant l'accent sur la personnalisation des contenus et la gamification.
 L'univers du marketing applicatif s'adapte en permanence aux changements en matière de respect de la vie privée sur iOS.
L'univers du marketing applicatif s'adapte en permanence aux changements en matière de respect de la vie privée sur iOS.
 Le projet de budget de la Sécurité sociale 2025 prévoit de décaler l'indexation des pensions de retraite sur l'inflation du 1er janvier au 1er juillet 2025.
Le projet de budget de la Sécurité sociale 2025 prévoit de décaler l'indexation des pensions de retraite sur l'inflation du 1er janvier au 1er juillet 2025.
DinMo, une startup spécialisée dans l’activation des données, annonce une levée de fonds de 5 millions d’euros. Ce financement additionnel vise à soutenir le développement de sa plateforme composable Customer Data Platform (CDP) et à accélérer son expansion internationale. Ce tour de financement a été mené par 468 Capital, avec la participation de Big Bets …
L’article DinMo lève 5 millions d’euros pour développer sa plateforme CDP alimentée par l’IA est apparu en premier sur FRENCHWEB.FR.
 Dans un rapport sur les finances locales, la Cour des comptes propose de faire "4,1 milliards d'euros par an à partir de 2030" en réduisant progressivement les effectifs d'agents publics.
Dans un rapport sur les finances locales, la Cour des comptes propose de faire "4,1 milliards d'euros par an à partir de 2030" en réduisant progressivement les effectifs d'agents publics.
 Les discussions devraient reprendre les termes de l'accord trouvé l'an dernier entre plusieurs partenaires sociaux, selon la ministre du Travail.
Les discussions devraient reprendre les termes de l'accord trouvé l'an dernier entre plusieurs partenaires sociaux, selon la ministre du Travail.
Corine Busson-Benhammou, directrice de la coopérative qui fédère start-up et industriels en Maine-et-Loire, a officialisé son départ pour les États-Unis, où elle prendra le poste de co-présidente de La French Tech Miami. Sur son compte LinkedIn, elle a partagé : « Il est des décisions qui transforment une vie, et aujourd’hui, je suis fière d’annoncer …
L’article Corine Busson-Benhammou quitte Angers pour prendre la co-présidence de La French Tech Miami est apparu en premier sur FRENCHWEB.FR.
 A l'occasion de la parution de trois publications de l'Alliance Digitale sur le DOOH programmatique, Clémence Maisonneuve (Cityz Media) et Alexandra Roa (Broadsign), membres du groupe de travail dédié, nous expliquent les raisons de la croissance assez marquée de ce levier.
A l'occasion de la parution de trois publications de l'Alliance Digitale sur le DOOH programmatique, Clémence Maisonneuve (Cityz Media) et Alexandra Roa (Broadsign), membres du groupe de travail dédié, nous expliquent les raisons de la croissance assez marquée de ce levier.
A l'occasion de la parution de trois publications de l'Alliance Digitale sur le DOOH programmatique, Clémence Maisonneuve (Cityz Media) et Alexandra Roa (Broadsign), membres du groupe de travail dédié, nous expliquent les raisons de la croissance assez marquée de ce levier.
 En tenant compte du temps passé à attendre les commandes, les travailleurs de certaines plateformes voient leur rémunération baisser depuis quelques années.
En tenant compte du temps passé à attendre les commandes, les travailleurs de certaines plateformes voient leur rémunération baisser depuis quelques années.
 Lors de son discours de politique générale devant l'Assemblée nationale ce mardi 1er octobre, le Premier ministre a évoqué de possibles ajustements sur la réforme des retraites, avec l'aide des partenaires sociaux.
Lors de son discours de politique générale devant l'Assemblée nationale ce mardi 1er octobre, le Premier ministre a évoqué de possibles ajustements sur la réforme des retraites, avec l'aide des partenaires sociaux.
 Le géant des puces a dévoilé un nouveau LLM open source à la pointe des performances en matière de compréhension visuelle. Le modèle surpasse GPT-4o en plusieurs points.
Le géant des puces a dévoilé un nouveau LLM open source à la pointe des performances en matière de compréhension visuelle. Le modèle surpasse GPT-4o en plusieurs points.
 Ce mardi 1er octobre, le débat entre J.D. Vance et Tim Walz, respectivement colistiers de Donald Trump et Kamala Harris, pourrait bien avoir été la dernière joute oratoire avant les élections.
Ce mardi 1er octobre, le débat entre J.D. Vance et Tim Walz, respectivement colistiers de Donald Trump et Kamala Harris, pourrait bien avoir été la dernière joute oratoire avant les élections.
Aujourd’hui, nous partons à la découverte de NumEthic, une association belge qui œuvre pour promouvoir le libre notamment dans les écoles. Pour commencer, pouvez-vous nous présenter NumEthic ? NumEthic est une association qui a pour but de promouvoir et de créer … Lire la suite
 L'industriel français compte déployer la GenAI au sein de ses systèmes de centre de commandement en vue d'améliorer le pilotage des forces armées sur le terrain.
L'industriel français compte déployer la GenAI au sein de ses systèmes de centre de commandement en vue d'améliorer le pilotage des forces armées sur le terrain.
 Les sommes placées dans ces plans d'épargne sont en hausse de plus de 10% par rapport à l'an dernier, portées par un nombre croissant d'entreprises mettant en place ces dispositifs.
Les sommes placées dans ces plans d'épargne sont en hausse de plus de 10% par rapport à l'an dernier, portées par un nombre croissant d'entreprises mettant en place ces dispositifs.
Most likely, you remember the experiences you had, not just the objects or things that you saw. That’s how humans work: we’re wired for stories and interactive journeys that engage all of our senses.
Whether you’re a freelance designer, illustrator, or an aspiring art director, navigating your career alone can be daunting. A mentor provides guidance, support, and insights that can help accelerate both your professional and personal growth.
 Michel Barnier a annoncé une revalorisation du Smic de 2% dès le 1 novembre. Il s'agit d'une revalorisation anticipée à celle du 1er janvier.
Michel Barnier a annoncé une revalorisation du Smic de 2% dès le 1 novembre. Il s'agit d'une revalorisation anticipée à celle du 1er janvier.
Learn how Federico Pian built his 2024 portfolio using Nuxt, GSAP, and TresJs, with insights into design inspiration, animation techniques, and seamless page transitions.
 Avec une présence accrue en Asie et des engagements solides dans le secteur des énergies vertes, le groupe pétrolier et gazier entend capitaliser sur sa dynamique de croissance mondiale.
Avec une présence accrue en Asie et des engagements solides dans le secteur des énergies vertes, le groupe pétrolier et gazier entend capitaliser sur sa dynamique de croissance mondiale.
Découvrez les méthodes originales utilisées pour faire fonctionner ce moyen de transport emblématique de la ville de San Francisco. Alors qu’ils montent et descendent les rues escarpées de la ville, les emblématiques téléphériques de San Francisco semblent glisser sans effort et sans aucun moyen de propulsion. Contrairement aux téléphériques traditionnels qui sont suspendus dans les airs, ces voitures ressemblant à des tramways rampent le long de la route, mais n’ont pas de câbles aériens visibles qui les alimentent en électricité. Au lieu de cela, elles sont actionnées par des câbles souterrains qui tournent en boucle sous les voies. Histoire des ...
Lire la suite : Les Cable Cars de San Francisco
Nous n'avons pas fini d'entendre parler de les LLM (grands modèles de langages) et de l'Intelligence Artificielle. Outre les sytèmes en ligne (souvent payants) il est possible d'interroger un modèle local (gratuitement) par l'intermédiaire d'un peu de JavaScript.
Pour ceci nous utiliserons :
- Ollama qui permet de télécharger des modèles au choix
- Un des modèles proposés, par exemple llama de Meta
- La bibliothèque JavaScript Ollama (package npm)
Ollama
Ollama est une application disponible pour Linux, macOS, Windows qui sert d'interface de gestion de LLM. Voyons la comme une sorte de Docker qui ira piocher dans un catalogue d'images disponibles en ligne, faciles à télécharger et à exécuter en une seule instruction ou presque en précisant bien le nom du modèle souhaité.
Les commandes essentielles après avoir téléchargé et installé Ollama :
ollama listliste les modèles déjà téléchargésollama pull <modèle>télécharge un nouveau LLMollama run <modèle>exécuteollama stop <modèle>met fin à l'exécutionollama rm <modèle>supprime
Pour l'occasion, nous utiliserons llama 3.2
ollama pull llama3.2
Pour préciser une autre version du modèle avec nombre de paramètres (comprenez complexité et poids) différent, on pourra par exemple indiquer ollama pull llama3.2:1b pour 1B soit un milliard de paramètres.
Jusque-là si tout va bien, nous pouvons d'ores et déjà discuter en mode texte brut par un ollama run llama3.2.
Package JavaScript Ollama
Cette bibliothèque nous permet d'aller interroger Ollama installé localement en définissant le modèle, le message à lui envoyer et en traitant la réponse. De manière très basique on peut se servir de console.log mais ce n'est pas très intéressant car bloquant jusqu'à obtenir la totalité de la réponse ; la promptitude du modèle dépendra aussi de la puissance de votre machine et de votre mémoire vive disponible.
À l'aide d'un environnement Node.js (déjà installé n'est-ce pas ?), nous pouvons poursuivre.
Créer un dossier quelconque ð pour notre projet.
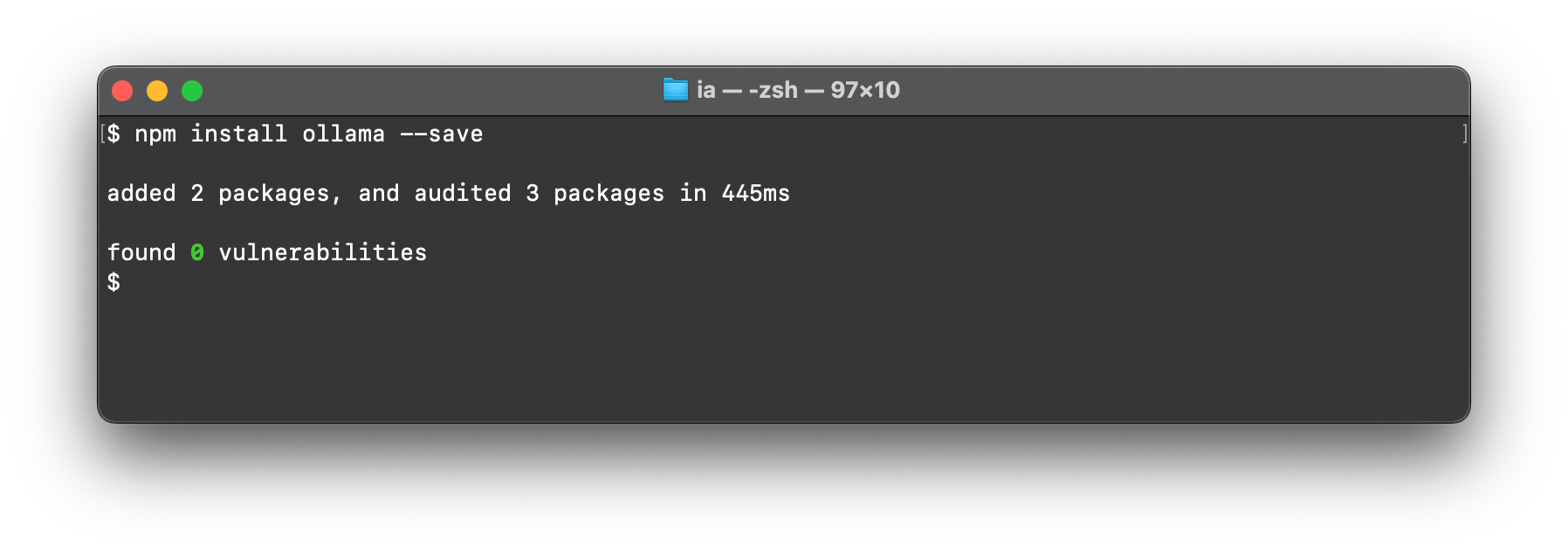
Installer la dépendnace avec
npm install --save ollama(ou avec pnpm)
- Écrire un petit script
kiwi.mjspour importerollamaet appelerchat()afin de lancer la discussion
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2',
messages: [{ role: 'user', content: 'Quelle est la recette du cake au kiwi ?' }],
})
// â ï¸ Ceci peut prendre beaucoup de temps car on attend la réponse complète
console.log(response.message.content)
Il suffira de l'exécuter en ligne de commande avec node kiwi.mjs.
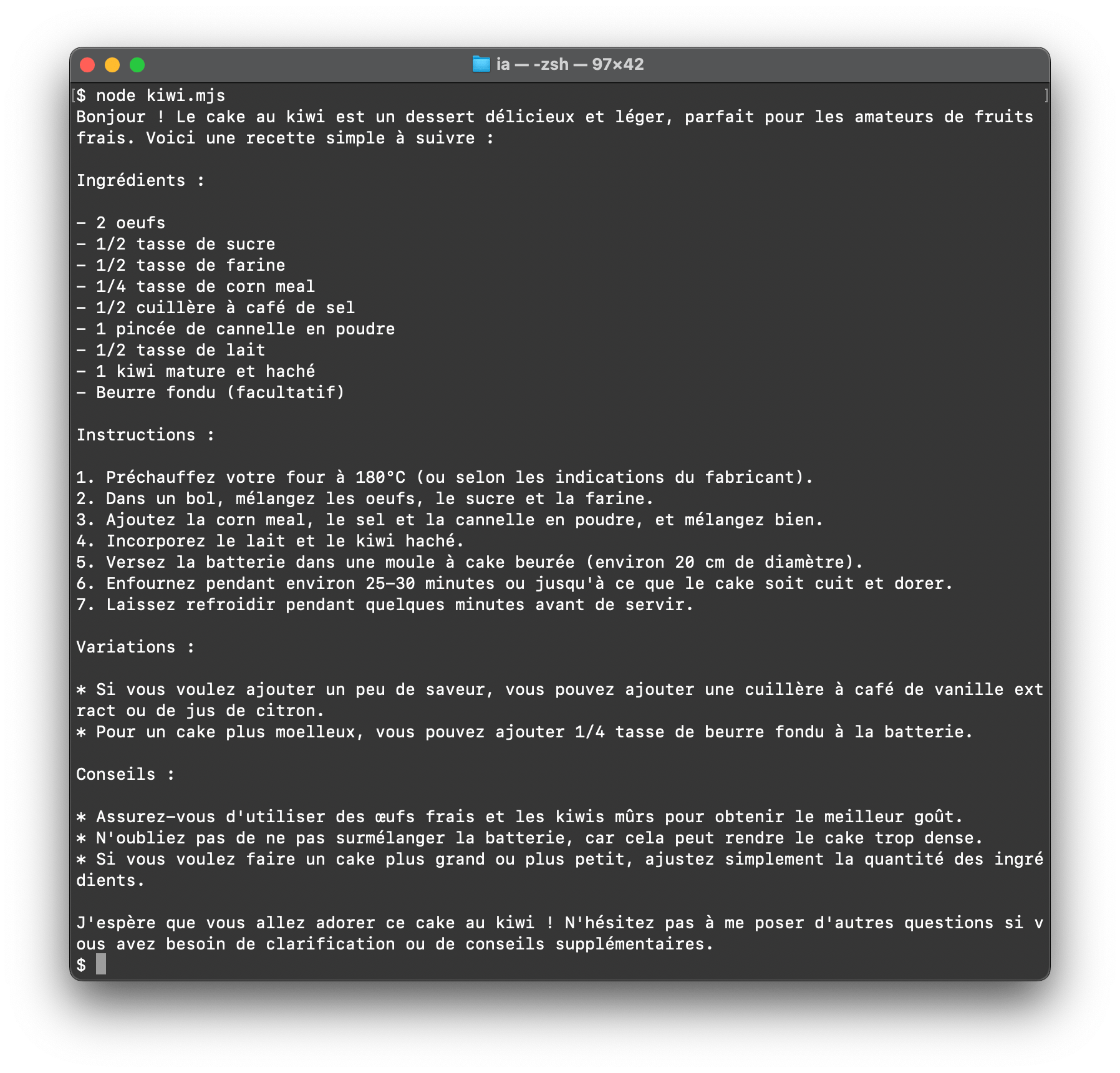
Pour streamer la réponse, c'est-à-dire la restituer au fur et à mesure de l'ajout de mots par le LLM, on peut se servir de l'alternative en activant l'option stream.
import ollama from 'ollama'
const message = { role: 'user', content: 'Quelle est la recette du cake au kiwi ?' }
const response = await ollama.chat({ model: 'llama3.2', messages: [message], stream: true })
for await (const part of response) {
process.stdout.write(part.message.content)
}
Un bon nombre d'autres paramètres et méthodes existent dans cette interface, il suffira de consulter la documentation pour les découvrir.
Et en application web ?
C'est possible ! Une page interrogera le modèle via ollama :
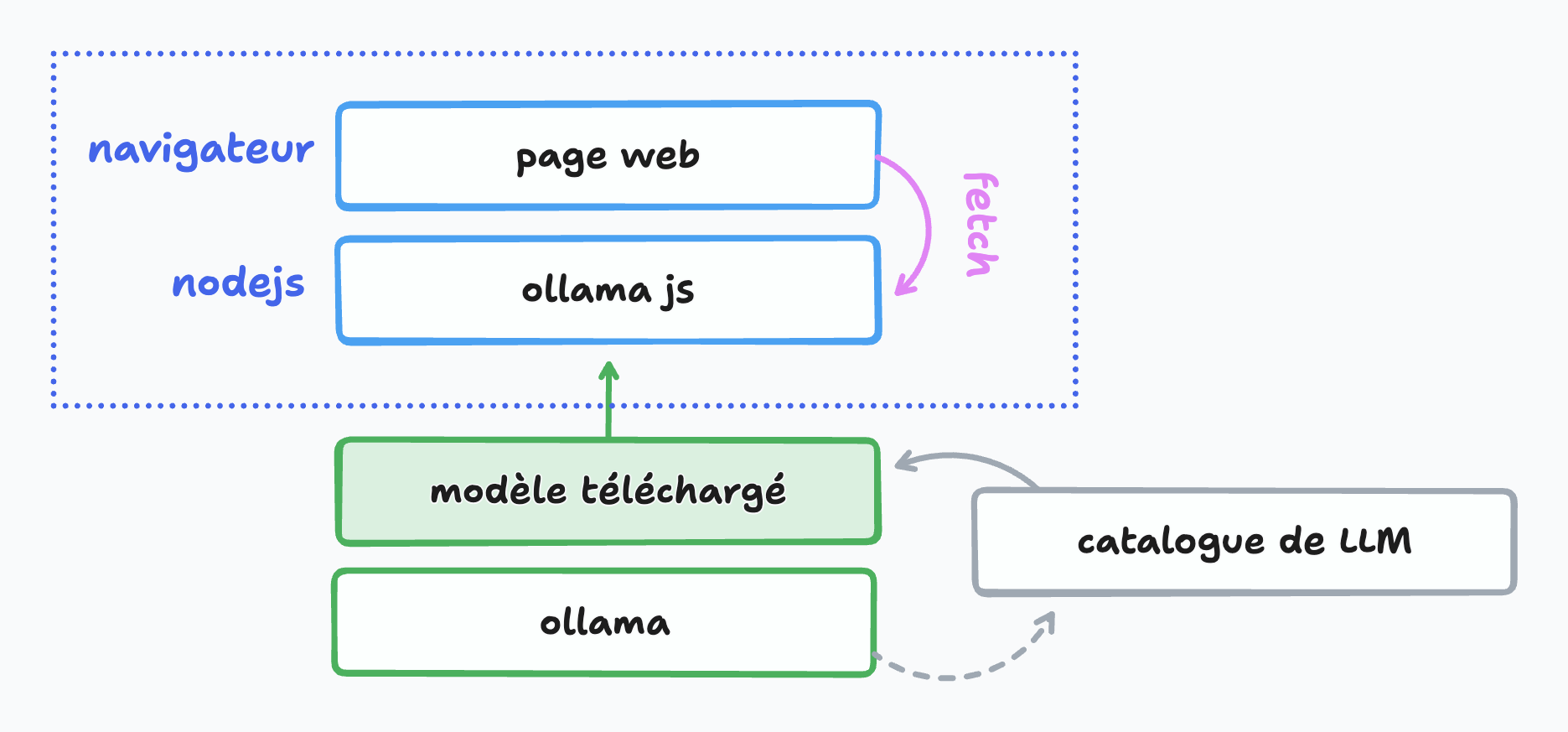
Pour transformer le tout en une petite application web utilisable dans le navigateur...
- Nous ajoutons
express
npm install --save express
Ce qui va permettre de construire un couple client/serveur minimaliste avec deux fichiers :
- server.mjs, qui sera à l'écoute des messages
- public/index.html, qui contiendra un formulaire et affichera le résultat
Les explications sont fournies par des commentaires dans le code source suivant, à vous de jouer en vous l'appropriant.
- Fichier
server.mjs
import express from 'express';
import ollama from 'ollama';
const app = express(); // Instance d'Express
const port = 3000; // Port à l'écoute
app.use(express.json());
// On sert le dossier public en statique, dans lequel on place notre page index.html
app.use(express.static('public'));
// On accepte les requêtes POST vers /chat
app.post('/chat', async (req, res) => {
// Notre message sera envoyé dans le corps de la requête (body)
const message = { role: 'user', content: req.body.content };
// La réponse provenant du LLM est une promesse
const response = await ollama.chat({ model: 'llama3.2', messages: [message], stream: true });
// La réponse envoyée à la page web dispose d'en-têtes HTTP
// ... permettant de faire persister la connexion
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive'
});
// Pour toute portion de réponse reçue, on la stream
for await (const part of response) {
res.write(`data: ${JSON.stringify(part.message)}\n\n`);
}
res.end();
});
// On écoute sur le port configuré
app.listen(port, () => {
console.log(`Serveur en écoute : http://localhost:${port}`);
});
- Page
public/index.htmlcorrespondante :
<!doctype html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>KiwIA</title>
<style>
/* à personnaliser selon vos envies */
body { font-family: system-ui; background: #222; color: #fff; padding: 2rem; }
#chat, [type=submit] { padding: 1rem; border-radius: 0.5rem; border: 1px solid #ccc; margin: 1rem 0; background: inherit; color: inherit; }
#chat { min-width: 20rem; font-size: inherit; }
#reponse { text-align: left; line-height: 2; }
</style>
</head>
<body>
<h1>Chat KiwIA ð¥</h1>
<form>
<input type="text" id="chat" placeholder="Votre message...">
<button type="submit">Envoyer</button>
</form>
<div id="reponse"></div>
<script>
const form = document.querySelector('form');
const input = document.querySelector('#chat');
const resultat = document.querySelector('#reponse');
// À la validation du formulaire
form.addEventListener('submit', async (e) => {
e.preventDefault();
// On récupère le contenu du message
const content = input.value.trim();
if (!content) return; // Si c'est vide on arrête là
// Petit message d'attente
resultat.textContent = 'Un instant et je suis à vous...';
// On vide le champ d'entrée
input.value = '';
try {
// Requête asynchrone en POST vers /chat
const response = await fetch('/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
// Corps de la requête en JSON
body: JSON.stringify({ content }),
});
resultat.textContent = '';
// On instancie une interface ReadableStream
const reader = response.body.getReader();
const decoder = new TextDecoder();
// Tant qu'on a du contenu...
while (true) {
const { done, value } = await reader.read(); // On lit
if (done) break;
const lines = decoder.decode(value).split('\n');
// On itère sur la réponse reçue pour alimenter le résultat
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
resultat.textContent += data.content;
}
}
}
} catch (error) {
console.error('Error:', error);
resultat.textContent = 'Une erreur est survenue.';
}
});
</script>
</body>
</html>
- On lance le tout grâce à
node server.mjset on consulte l'adresse indiquée dans le navigateur pour atteindre la page HTML qui affiche le formulaire.
On peut perfectionner le rendu en mettant en page le message renvoyé sous forme de markdown (mais cela dépend du modèle interrogé) plutôt que de l'afficher en texte brut.
Perspectives
On peut voir que construire une application web sollicitant un LLM est tout à fait envisageable avec les technologies d'aujourd'hui et les standards déjà en place (HTML/CSS, JavaScript, fetch, Streams API, etc). À partir de là tout est possible pour imaginer élaborer des interfaces qui vont dialoguer en texte clair ou par d'autres moyens plus subtiles, et réagir en conséquence. Vous pouvez aussi briefer votre LLM en amont et lui donner des instructions ou un contexte de réponse, voire en construire un nouveau (avec l'instruction FROM de Ollama).
Pour pousser l'horizon encore plus loin, faire tourner des LLM dans le navigateur lui-même est possible grâce à WebGPU (voir une démo ici : Qwen-2.5 on WebGPU sur Huggingface) avec une performance tout à fait honorable.
Les concepteurs de navigateurs préparent des interfaces aisées d'accès en JavaScript pour interroger un modèle local, tels que Google avec l'IA Gemini intégrée dans Chrome. Nous n'avons pas fini d'en entendre parler.
Retrouvez l'intégralité de ce tutoriel en ligne sur Alsacreations.com
Nous n'avons pas fini d'entendre parler de les LLM (grands modèles de langages) et de l'Intelligence Artificielle. Outre les sytèmes en ligne (souvent payants) il est possible d'interroger un modèle local (gratuitement) par l'intermédiaire d'un peu de JavaScript.
Pour ceci nous utiliserons :
- Ollama qui permet de télécharger des modèles au choix
- Un des modèles proposés, par exemple llama de Meta
- La bibliothèque JavaScript Ollama (package npm)
Ollama
Ollama est une application disponible pour Linux, macOS, Windows qui sert d'interface de gestion de LLM. Voyons la comme une sorte de Docker qui ira piocher dans un catalogue d'images disponibles en ligne, faciles à télécharger et à exécuter en une seule instruction ou presque en précisant bien le nom du modèle souhaité.
Les commandes essentielles après avoir téléchargé et installé Ollama :
ollama listliste les modèles déjà téléchargésollama pull <modèle>télécharge un nouveau LLMollama run <modèle>exécuteollama stop <modèle>met fin à l'exécutionollama rm <modèle>supprime
Pour l'occasion, nous utiliserons llama 3.2
ollama pull llama3.2
Pour préciser une autre version du modèle avec nombre de paramètres (comprenez complexité et poids) différent, on pourra par exemple indiquer ollama pull llama3.2:1b pour 1B soit un milliard de paramètres.
Jusque-là si tout va bien, nous pouvons d'ores et déjà discuter en mode texte brut par un ollama run llama3.2.
Package JavaScript Ollama
Cette bibliothèque nous permet d'aller interroger Ollama installé localement en définissant le modèle, le message à lui envoyer et en traitant la réponse. De manière très basique on peut se servir de console.log mais ce n'est pas très intéressant car bloquant jusqu'à obtenir la totalité de la réponse ; la promptitude du modèle dépendra aussi de la puissance de votre machine et de votre mémoire vive disponible.
À l'aide d'un environnement Node.js (déjà installé n'est-ce pas ?), nous pouvons poursuivre.
Créer un dossier quelconque ð pour notre projet.
Installer la dépendnace avec
npm install --save ollama(ou avec pnpm)
- Écrire un petit script
kiwi.mjspour importerollamaet appelerchat()afin de lancer la discussion
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2',
messages: [{ role: 'user', content: 'Quelle est la recette du cake au kiwi ?' }],
})
// â ï¸ Ceci peut prendre beaucoup de temps car on attend la réponse complète
console.log(response.message.content)
Il suffira de l'exécuter en ligne de commande avec node kiwi.mjs.
Pour streamer la réponse, c'est-à-dire la restituer au fur et à mesure de l'ajout de mots par le LLM, on peut se servir de l'alternative en activant l'option stream.
import ollama from 'ollama'
const message = { role: 'user', content: 'Quelle est la recette du cake au kiwi ?' }
const response = await ollama.chat({ model: 'llama3.2', messages: [message], stream: true })
for await (const part of response) {
process.stdout.write(part.message.content)
}
Un bon nombre d'autres paramètres et méthodes existent dans cette interface, il suffira de consulter la documentation pour les découvrir.
Et en application web ?
C'est possible ! Une page interrogera le modèle via ollama :
Pour transformer le tout en une petite application web utilisable dans le navigateur...
- Nous ajoutons
express
npm install --save express
Ce qui va permettre de construire un couple client/serveur minimaliste avec deux fichiers :
- server.mjs, qui sera à l'écoute des messages
- public/index.html, qui contiendra un formulaire et affichera le résultat
Les explications sont fournies par des commentaires dans le code source suivant, à vous de jouer en vous l'appropriant.
- Fichier
server.mjs
import express from 'express';
import ollama from 'ollama';
const app = express(); // Instance d'Express
const port = 3000; // Port à l'écoute
app.use(express.json());
// On sert le dossier public en statique, dans lequel on place notre page index.html
app.use(express.static('public'));
// On accepte les requêtes POST vers /chat
app.post('/chat', async (req, res) => {
// Notre message sera envoyé dans le corps de la requête (body)
const message = { role: 'user', content: req.body.content };
// La réponse provenant du LLM est une promesse
const response = await ollama.chat({ model: 'llama3.2', messages: [message], stream: true });
// La réponse envoyée à la page web dispose d'en-têtes HTTP
// ... permettant de faire persister la connexion
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive'
});
// Pour toute portion de réponse reçue, on la stream
for await (const part of response) {
res.write(`data: ${JSON.stringify(part.message)}\n\n`);
}
res.end();
});
// On écoute sur le port configuré
app.listen(port, () => {
console.log(`Serveur en écoute : http://localhost:${port}`);
});
- Page
public/index.htmlcorrespondante :
<!doctype html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>KiwIA</title>
<style>
/* à personnaliser selon vos envies */
body { font-family: system-ui; background: #222; color: #fff; padding: 2rem; }
#chat, [type=submit] { padding: 1rem; border-radius: 0.5rem; border: 1px solid #ccc; margin: 1rem 0; background: inherit; color: inherit; }
#chat { min-width: 20rem; font-size: inherit; }
#reponse { text-align: left; line-height: 2; }
</style>
</head>
<body>
<h1>Chat KiwIA ð¥</h1>
<form>
<input type="text" id="chat" placeholder="Votre message...">
<button type="submit">Envoyer</button>
</form>
<div id="reponse"></div>
<script>
const form = document.querySelector('form');
const input = document.querySelector('#chat');
const resultat = document.querySelector('#reponse');
// À la validation du formulaire
form.addEventListener('submit', async (e) => {
e.preventDefault();
// On récupère le contenu du message
const content = input.value.trim();
if (!content) return; // Si c'est vide on arrête là
// Petit message d'attente
resultat.textContent = 'Un instant et je suis à vous...';
// On vide le champ d'entrée
input.value = '';
try {
// Requête asynchrone en POST vers /chat
const response = await fetch('/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
// Corps de la requête en JSON
body: JSON.stringify({ content }),
});
resultat.textContent = '';
// On instancie une interface ReadableStream
const reader = response.body.getReader();
const decoder = new TextDecoder();
// Tant qu'on a du contenu...
while (true) {
const { done, value } = await reader.read(); // On lit
if (done) break;
const lines = decoder.decode(value).split('\n');
// On itère sur la réponse reçue pour alimenter le résultat
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
resultat.textContent += data.content;
}
}
}
} catch (error) {
console.error('Error:', error);
resultat.textContent = 'Une erreur est survenue.';
}
});
</script>
</body>
</html>
- On lance le tout grâce à
node server.mjset on consulte l'adresse indiquée dans le navigateur pour atteindre la page HTML qui affiche le formulaire.
On peut perfectionner le rendu en mettant en page le message renvoyé sous forme de markdown (mais cela dépend du modèle interrogé) plutôt que de l'afficher en texte brut.
Perspectives
On peut voir que construire une application web sollicitant un LLM est tout à fait envisageable avec les technologies d'aujourd'hui et les standards déjà en place (HTML/CSS, JavaScript, fetch, Streams API, etc). À partir de là tout est possible pour imaginer élaborer des interfaces qui vont dialoguer en texte clair ou par d'autres moyens plus subtiles, et réagir en conséquence. Vous pouvez aussi briefer votre LLM en amont et lui donner des instructions ou un contexte de réponse, voire en construire un nouveau (avec l'instruction FROM de Ollama).
Pour pousser l'horizon encore plus loin, faire tourner des LLM dans le navigateur lui-même est possible grâce à WebGPU (voir une démo ici : Qwen-2.5 on WebGPU sur Huggingface) avec une performance tout à fait honorable.
Les concepteurs de navigateurs préparent des interfaces aisées d'accès en JavaScript pour interroger un modèle local, tels que Google avec l'IA Gemini intégrée dans Chrome. Nous n'avons pas fini d'en entendre parler.
Retrouvez l'intégralité de ce tutoriel en ligne sur Alsacreations.com
Pinterest est avant tout considéré comme une plateforme dédiée au partage d’images. Mais saviez-vous qu’elle pourrait être la clé du renouveau de votre trafic organique ? Longtemps sous-estimée par rapport aux réseaux sociaux comme Facebook ou Instagram, Pinterest n’en reste pas moins une interface intéressante à exploiter, surtout si vous alimentez régulièrement un blog de qualité. Avec un peu plus de 16 millions d’utilisateurs réguliers en France en 2024 et des épingles à l’incroyable longévité, la puissance du trafic organique potentiellement généré est bien réelle. Pinterest se fraie donc progressivement un chemin vers la popularité. Pour autant, le réseau à la punaise … Lire la suite
Lire la suite : Pinterest, la solution magique pour votre trafic organique ?
 La Fédération du commerce et de la distribution a vivement réagi à une phrase prononcée par le Premier ministre lors de sa déclaration de politique générale.
La Fédération du commerce et de la distribution a vivement réagi à une phrase prononcée par le Premier ministre lors de sa déclaration de politique générale.
 Une séance contrastée ce mercredi pour les places financières mondiales, marquée par un regain de dynamisme en Asie et une vigilance accrue en Europe et aux Etats-Unis face aux tensions internationales.
Une séance contrastée ce mercredi pour les places financières mondiales, marquée par un regain de dynamisme en Asie et une vigilance accrue en Europe et aux Etats-Unis face aux tensions internationales.
 Le recours à ce format reste confidentiel, mais les retours semblent prometteurs, avec en particulier un taux de conversion 300 fois supérieur à celui d'une campagne classique.
Le recours à ce format reste confidentiel, mais les retours semblent prometteurs, avec en particulier un taux de conversion 300 fois supérieur à celui d'une campagne classique.
Au-delà du simple engouement médiatique, l’IA transforme concrètement le paysage de la création vidéo pour les marques. Automatisation de la post-production, personnalisation du contenu à l’échelle, et génération d’expériences immersives sont désormais à la portée des entreprises, grandes et petites. ð Inscrivez-vous gratuitement en cliquant ici Mais quels sont les véritables avantages pour les marques …
L’article Live talk : IA & vidéo, au-delà de l’écho médiatique, quelles applications concrètes pour les marques ? est apparu en premier sur FRENCHWEB.FR.
Edit : J’ai écris cet article en mai 2024 et programmé pour le 2 octobre de cette année. Malheureusement, entre temps, le développeur a clôturé son projet. Désolé pour ça.
Terminé les réglages planqués dans tous les coins sous Windows, les applis pré-installées qui bouffent de la place pour rien, et cette satanée IA Copilot qui fourre son nez partout. Avec Winpilot, vous allez pouvoir reprendre les commandes et façonnez votre Windows à votre image. Et tout ça, avec la complicité de Clippy, le fidèle assistant tout droit sorti des années 90 !
 La nouveauté permet de retoucher des images en quelques clics. Pratique pour les petits e-commerçants, même si certaines précautions sont à observer.
La nouveauté permet de retoucher des images en quelques clics. Pratique pour les petits e-commerçants, même si certaines précautions sont à observer.
Formality, startup basée à Paris, spécialisée dans la gestion des contrats par intelligence artificielle (IA), annonce une levée de fonds de 8 millions d’euros. Ce tour de table a été mené par les fonds de capital-risque Partech et Serena, avec une contribution supplémentaire de 2,4 millions d’euros de la part de BPI France. Cette levée …
L’article Formality lève 8 millions d’euros pour le développement de sa plateforme de gestion contractuelle alimentée par l’IA est apparu en premier sur FRENCHWEB.FR.
Let me teach you how to animate the CSS Grid properties by building a responsive image grid with hover effects.
As a UX designer, it is important to build empathy and celebrate accessibility requirements as a set of design constraints to build a better product.
In user experience (UX) research, asking users “Why?” is a fundamental practice aimed at uncovering the motivations behind their behaviours and preferences. On the surface, this approach seems straightforward: by understanding the reasons users provide, we can design products that better meet their needs. However, psychological research suggests that the effectiveness of “Why?” questions is more complex than it appears.
When it comes to on-page SEO, there’s one element that plays a pivotal role in both search engine rankings and user engagement: the HTML title tag. Often overlooked, this small but mighty piece of code can have a significant impact on how your website is perceived by search engines like Google and by potential visitors browsing the search engine results pages.
 Rémy Cadeau, directeur des opérations chez Free Pro, explique en quoi la Solution Cyber XPR est unique sur le marché français.
Rémy Cadeau, directeur des opérations chez Free Pro, explique en quoi la Solution Cyber XPR est unique sur le marché français.
Nous en parlons régulièrement sur FRENCHWEB.FR, l’ABM est l’une des approches marketing parmi les plus interessantes pour développer ses actions commerciales. L’ABM (Account-Based Marketing) vise à cibler les clients potentiels individuellement au lieu de les cibler en tant que groupe. L’ABM implique la création de stratégies marketing et de vente personnalisées pour chaque client potentiel …
L’article Les mots clés de l’ABM à connaitre en 2024 est apparu en premier sur FRENCHWEB.FR.
Le textile est la deuxième industrie la plus polluante dans le monde. On estime en effet que 10% des émissions mondiales de gaz à effet de serre sont dues à cette industrie. Face à ce constat, certaines marques tentent de s’engager en limitant leurs émissions de carbone. C’est dans ce contexte que la startup Carbonfact …
L’article Connaissez-vous CARBONFACT, solution permettant aux marques de mode de maîtriser leur empreinte carbone? est apparu en premier sur FRENCHWEB.FR.
 Un financement qui permettra notamment à la start-up de recruter une dizaine de collaborateurs et de se lancer aux Etats-Unis en 2025.
Un financement qui permettra notamment à la start-up de recruter une dizaine de collaborateurs et de se lancer aux Etats-Unis en 2025.