Alsacreations.com - Actualités - Archives (avril 2015)
Les dernières actualités d'Alsacreations.com
Voici une idée simple et efficace (comme je les aime) qui fait son chemin : le format .json. Ce format, provenant du monde JavaScript et représentant un objet, s'apparente au .XML, dans sa fonction du moins : il permet de stocker des données textuelles (mais pas des données binaires) de manière structurée.
Il a été créé par Douglas Crockford qui l'a décrit en 2006 par la RFC4627 de l'IETF. Cette référence a été mise à jour en 2014 dans la RFC7159.
Avantages et inconvénients
Vous allez vous rendre compte que ce format ne présente pas beaucoup de défauts (mais peut-être ne suis-je pas tout à fait objectif en disant cela), principalement parce qu'il reste vraiment très simple à lire, comprendre et utiliser.
Les plus
- Langage compréhensible par tous (humain et machine). Aucun apprentissage n'est requis puisque la syntaxe n'utilise que quelques marques de ponctuations (nous le verrons plus tard).
- Ne dépend d'aucun langage (format d'échange de données ouvert).Comme ce format est très ouvert, il est pris en charge par de nombreux langages : JavaScript, PHP, Perl, Python, Ruby, Java,...
- Permet de stocker des données de différents types : chaînes de caractères (y compris des images en base64), nombres, tableaux (array), objets.
- Sa structure en arborescence et sa syntaxe simple lui permet de rester très "léger" et efficace.
Les moins
- Ne convient pas au stockage de données sensibles.
- Le fait que la syntaxe soit rudimentaire peut être un inconvénient dans certains cas. Par exemple, contrairement à XML, il n'y a pas d'identification précise des données (sous forme de balise par exemple), la structure doit donc être connue avant utilisation.
La syntaxe
Je vous parlais précédemment de quelques signes de ponctuations qui permettent de structurer les données dans un fichier .json. En voici la liste (vous ne serez normalement pas dépaysés puisqu'ils sont utilisés exactement de la même manière dans d'autres langages, comme JavaScript par exemple) :
-
{...}: les accolades définissent un objet. -
"language":"Java": Les guillemets (double-quotes) et les double-points définissent un couple clé/valeur (on parle de membre). -
[...]: Les crochets définissent un tableau (ou array en anglais). -
{"id":1, "language":"json", "author":"Douglas Crockford"}: Les virgules permettent de séparer les membres d'un tableau ou, comme ici, d'un objet . A noter : pas de virgule pour le dernier membre d'un objet, sinon, il ne sera pas valide et vous aurez des erreurs lors de l'analyse du fichier.
C'est tout ? Ben oui, c'est tout ! Une dernière précision cependant, et elle n'est pas anodine : tout doit être encodé en utf-8.
Il est temps de découvrir un exemple de fichier .json basique :
{
"titre_album":"Abacab",
"groupe":"Genesis",
"annee":1981,
"genre":"Rock"
}
Suffisamment simple pour ne pas avoir à donner d'explications, non ? Un fichier .json contient un objet ({...}) qui, ici, contient 4 membres identifiés par leurs paires clé/valeur. Les valeurs possibles sont :
-
Une chaîne de caractères :
"titre":"Le format json", "description":"Le format <strong>simple</strong> et <strong>léger</strong>, "contenu":"<p>L'avantage de json est son incroyable simplicité d'apprentissage et de mise en oeuvre. C'est le \"Petit Poucet\" de l'échange de données.</p>" -
Un nombre (pas de guillemets requis dans ce cas) :
"pi":3.14, "g":9.81, "v_son":340 -
Un tableau :
[...] -
Un objet :
{...} -
D'autres valeurs possibles : un booléen (true ou false), null, rien (
"alsanaute":true, "autrenaute":null,"bisounaute":"")
Sachez qu'il est possible d'ajouter autant d'espaces (au sens large du terme, c'est à dire que les retours à la ligne et les tabulations sont également considérés comme des espaces) que l'on veut. Le fichier ci-dessus pourra donc également s'écrire de la manière suivante, par exemple :
{
"titre_album"
:"Abacab",
"groupe"
:"Genesis",
"annee"
:1981,
"genre"
:"Rock"
}
Voyons à présent un exemple plus complexe contenant des objets et des tableaux :
{
"fruits": [
{ "kiwis": 3,
"mangues": 4,
"pommes": null
},
{ "panier": true }
],
"legumes": {
"patates": "amandine",
"poireaux": false
},
"viandes": ["poisson","poulet","boeuf"]
}
Dans cet exemple nous pouvons observer qu'il y a 3 membres (fruits, legumes et viandes). fruits est constitué d'un seul membre qui est un tableau de 2 objets : le premier objet contient 3 membres et le second un seul. legumes est défini par un objet constitué par 2 membres. viandes, quant à lui, est défini par un tableau de 3 éléments.
Cet exemple démontre l'extraordinaire récursivité (illimitée ou presque : 512 niveaux acceptés !) de ce type de format, encore une grande qualité à mettre à l'actif de .json !
Visualisation et validation
Quand on débute dans un langage, le fait d'avoir à disposition des outils permettant de visualiser et de valider le code est d'une grande aide. Là encore .json est doté de tout ce dont vous avez besoin. En effet, plusieurs visualiseurs/validateurs sont disponibles en ligne. Un des visualiseurs les plus connu est jsonviewer.stack.hu. Le grand avantage de cet outil est qu'il intègre toutes les fonctionnalités utiles pour l'analyse d'un fragment de code .json : un validateur (très basique puisqu'il ne fait qu'indiquer si le code contient des erreurs), un visualiseur, un minificateur. Le principe est simple, vous collez le code dans la fenêtre "Text" puis vous cliquez sur l'onglet "Viewer". S'il n'y a pas d'erreur dans votre code, l'arborescence de votre .json sera affichée. Copie d'écran pour le dernier exemple traité :
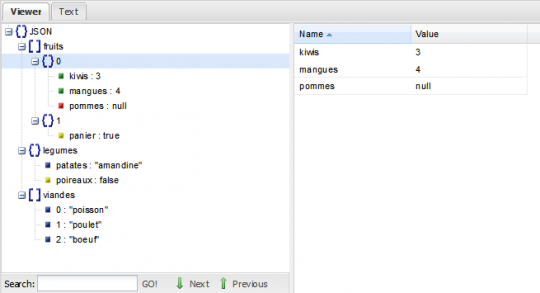
Pour la minification, Il suffit de cliquer sur le bouton "Remove white spaces". Pour revenir à la version formatée ou pour formater un fichier non formaté, cliquez sur le bouton "Format".
Le validateur se contente d'indiquer qu'il y a une erreur dans le code analysé, c'est un peu léger pour le débogage, qu'à cela ne tienne, il existe d'autres outils plus performants pour cela (ils indiquent l'endroit où se trouve l'erreur). Un exemple parmi d'autres : JSONLint.
D'autres outils disponibles en ligne :
- Formatage et validation : JSON Formatter & Validator
- Editeur et formatage : JSON Editor Online
- …
PHP et json
Généralités
Le format .json est une notation héritée de JavaScript que l'on peut considérer comme un objet, c'est donc dans ce langage-là qu'ont été développés en premier des fonctions de prise en charge, notamment pour AJAX, pour lequel il permet de linéariser des données de requêtes. Rodolphe nous avait concocté un article à ce sujet : « Le format JSON, AJAX et jQuery ».
Mais, comme dit au début de ce tutoriel, beaucoup d'autres langages prennent en charge .json. Parmi eux, PHP.
Dans un premier temps, il était nécessaire d'installer une bibliothèque sur le serveur afin d'obtenir des outils de traitement, mais à présent (à partir de la version 5.2), ces outils sont intégrés dans le noyau de php, du moins les deux fonctions de décodage et d'encodage json entre autres : json_decode() et json_encode() . Nous utiliserons la première fonction dans le cas d'étude qui va suivre.
json pour la traduction de chaînes
Nous connaissons différents langages permettant l'internationalisation de fichiers, le plus connu d'entre eux étant gettext de la Free Software Foundation (FSF) (uniquement développé à des fins de traduction et utilisé notamment par différents CMS tel que WordPress), mais également d'autres langages pas uniquement dédié à cela comme XML, YAML. Ils ont tous fait leur preuve et sont donc fiables. Cependant, ils se trouvent être assez "lourd" et demandent donc des ressources certaines lors de leur analyse. C'est pourquoi, opter pour un (ou plusieurs) fichier .json semble être une alternative intéressante dans le cadre de "petits" projets à traduire. Il est léger, très rapide à analyser et garde les avantages de lisibilité qu'ont les moyens énumérés précédemment.
Nous allons donc voir comment mettre en place un système d'internationalisation de fichier en utilisant ce format. Voici le code du fichier que je vous propose de traiter :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Alsacreafans</title>
<meta name="description" content="Communauté des fans d'Alsacreations.com">
</head>
<body>
<header>
<h1>Les alsacreafans</h1>
<p>Nous pensons qu'Alsacreations est une initiative d'<a href="http://vosdroits.service-public.fr/associations/F1131.xhtml">utilité publique</a> !</p>
</header>
<main>
<article>
<header>
<h2>Vos avis</h2>
</header>
<p>Quelques commentaires des fans :</p>
<blockquote>
<p>Des tutoriels très clairs, des articles toujours à la pointe de l'actualité !</p>
</blockquote>
<blockquote>
<p>Vous obtenez des avis de "pros" dans le forum d'Alsacreations.com !</p>
</blockquote>
<blockquote>
<p>Ma veille technologique passe par le flux RSS et la timeline Twitter d'Alsacreations.com !</p>
</blockquote>
</article>
</main>
<footer>
<p>
© Alsacreafans.com 2015 | Cet exemple de page html n'est pas de la responsabilité d'Alsacreations.com et n'a été mis en place que pour des raisons didactiques.
</p>
</footer>
</body>
</html>
Nous allons donc créer un fichier fr.json qui stockera les chaînes en français, le voici (il faudra faire de même pour les autres langues, dans la démonstartion ci-dessous, un fichier en.json) :
{
"head_title":"Les Alsacreafans",
"head_description":"Communauté des fans d'Alsacreations.com",
"site_h1":"Les Alsacreafans",
"site_description":"Nous pensons qu'Alsacreations est une initiative d'<a href=\"http://vosdroits.service-public.fr/associations/F1131.xhtml\">utilité publique</a> !",
"page_h2":"Vos avis",
"page_content":"<p>Quelques commentaires des fans :</p><blockquote><p>Des tutoriels très clairs, des articles toujours à la pointe de l'actualité !</p></blockquote><blockquote><p>Vous obtenez des avis de \"pros\" dans le forum d'Alsacreations !</p></blockquote><blockquote><p>Ma veille technologique passe par le flux RSS et la timeline Twitter d'Alsacreations !</p></blockquote>",
"footer_text":"© Alsafans.com 2015 | Cet exemple de page html n'est pas de la responsabilité d'Alsacreations.com et n'a été mis en place que pour des raisons didactiques."
}
Quelques commentaires à propos de ce fichier :
-
Les clés sont écrites en anglais, langue de référence pour les traducteurs. Elles sont écrites en minuscule et les mots sont séparés par des "underscores" pour faciliter la sélection au double-clic. Il est tout à fait possible, d'après mes tests, d'utiliser des espaces dans les noms de clé. Par exemple,
"The site header"est une valeur valide.Attention, les clés sont sensibles à la casse (
"Site_H1"≠"site_h1") - Dans notre exemple, la valeur de page_content ne doit pas comporter de retours à la ligne qui rendent le fichier invalide. Cela peut arriver lorsque l'on fait un copier/coller de la source.
-
Les commentaires ne sont pas pris en charge par le format
.json. Mais une petite astuce pourra faire l'affaire : il suffit d'ajouter un membre assez visible et qui ne sera pas pris en compte pour la traduction. Par exemple :"Top_page_infos":"##########################"
Le fichier à internationaliser (qui est en fait un fichier .php) sera modifié de la manière suivante :
<?php
$lang = $fr_class = $en_class = '';
/* Récupération de la langue dans la chaîne get */
$lang = (isset($_GET['lang']) && file_exists('lang/'.$_GET['lang'].'.json')) ? $_GET['lang'] : 'fr';
/* Définition de la class pour les liens de langue */
if ($lang == 'fr')
$fr_class = ' class="active"';
else
$en_class = ' class="active"';
/* Récupération du contenu du fichier .json */
$contenu_fichier_json = file_get_contents('lang/'.$lang.'.json');
/* Les données sont récupérées sous forme de tableau (true) */
$tr = json_decode($contenu_fichier_json, true);
?>
<!DOCTYPE html>
<html lang="<?php echo $lang ?">
<head>
<meta charset="utf-8">
<title><?php echo $tr['head_title'] ?></title>
<meta name="description" content="<?php echo $tr['head_description'] ?>">
</head>
<body>
<header>
<h1><?php echo $tr['site_h1'] ?></h1>
<p><?php echo $tr['site_description'] ?></p>
</header>
<nav><a<?php echo $en_class ?> href="?lang=en">en</a> <a<?php echo $fr_class ?> href="?lang=fr">fr</a></nav>
<main>
<article>
<header>
<h2><?php echo $tr['page_h2'] ?></h2>
</header>
<?php echo $tr['page_content'] ?>
</article>
</main>
<footer>
<p>
<?php echo $tr['footer_text'] ?>
</p>
</footer>
</body>
</html>
Là encore quelques commentaires…
-
Le code php est pour le moins simplissime :
- Récupération du code iso de la langue dans la chaîne get ;
- définition de la class des liens de langue (pour le style des deux boutons selon l'état) ;
-
récupération du contenu du fichier
fr.jsonouen.json; - décodage du fichier ;
-
On retrouve toutes les valeurs sous forme de tableau associatif si on ajoute le paramètre
trueà la fonctionjson_decode(), sinon on les obtient sous forme d'objet.site_h1par exemple, serait récupéré ainsi :$fr->{'site_h1'}. -
On peut bien évidemment améliorer ce système d'internationalisation en créant des fonctions de traitement des traductions avant affichage à l'instar de la fonction
_()de gettext.
Ici, nous avons vu un cas très simple de décodage de fichier .json. La récursivité d'un tel fichier est tout aussi simple à prendre en compte, vous pouvez d'ailleurs vous aider des visualiseurs json pour retrouver les différents éléments de l'objet. Pour l'exemple json complexe, vous récupérerez la valeur de "mangues" par $fr['fruits'][0]['mangues'] (si vous utilisez le même code php que je vous propose ci-dessus).
Ressources
- Le site officiel de JSON
- JSON pour les débutants (désolé, en anglais et désolé pour l'image complètement hors de propos)
- Un autre tutoriel JSON (encore en anglais)
- Tutoriel JSON sur XUL.fr
Le 19 Juin pour tous ceux veulent causer front il y a la KiwiParty.
Mais si vous n'avez pas la chance de pouvoir y aller ou que vous êtes plutôt orienté back office et CMS alors je vous encourage à aller voir du coté de Drupagora.
Il s'agit du premier événement sur Drupal orienté fonctionnel, le salon aura lieu sur toute une journée à Paris le 19 Juin.
Cette année, le fil rouge du programme est : « Drupal dans le contexte de l'Entreprise: plateformes digitales globales, applications eCommerce, applications métier jumelées et intégrées au SI (ERP, CRM, PIM, DAM…). »
Avec pour thématiques principales :
- Comment Drupal s'intègre t-il avec d'autres applications métier?
- Exemples réussis et témoignages d'applications Drupal d'envergure et de E-commerce
- Les perspectives avec l'arrivée prochaine de Drupal 8
Date, lieu et organisation
La conférence Drupagora se tient à l'Université Pierre et Marie Curie, Paris 5ème, le vendredi 19 juin de 9h à 18h.
Tarif / Inscription
- 40 euros jusqu'au 01/05/2015
- 75 euros jusqu'au 15/06/2015
- 100 euros en tarif normal

Vous le savez sans doute déjà si vous suivez le flux Twitter @alsacreations, nous organisons cette année encore notre évènement annuel : la KiwiParty à Strasbourg, le vendredi 19 juin 2015.
Le programme est d'ailleurs quasiment finalisé et les orateurs retenus !
Nous tenons à ce que la participation soit gratuite comme chaque année, ce qui implique un nombre de places limité (mais tout de même 200 !) et donc une procédure d'inscription en ligne à suivre à la lettre ;)
Cette année nous allons faire deux salves de pré-inscriptions de 100 places chacune:
- Mardi 28 avril à 10h42 (100 places)
- Jeudi 14 mai à 13h37 (100 places)
Une fois les 100 places prises lors de la seconde vague (jeudi 14 mai), ceux qui n'auront pas eu de place serons mis en liste d'attente.
ATTENTION il s'agit là de pré-inscriptions. Un e-mail de validation sera nécessaire pour confirmer votre venue. Après le 21 mai, les places non confirmées seront attribuées aux personnes sur liste d'attente.
