Alsacreations.com - Actualités - Archives (novembre 2012)
Les dernières actualités d'Alsacreations.com
Cet ouvrage en français, traduit de sa version originale américaine, est certainement l'un des mieux présentés que j'ai pu lire dans ce domaine.
Ce livre souhaite s'adresser à trois cibles précises : les débutants qui souhaitent découvrir les langages HTML et CSS, les éditeurs de contenu web qui souhaitent proposer une plus-value à leurs contenus, et les professionnels qui tiennent à enrichir leurs connaissances.
Dès le début de la lecture, il est assez surprenant et agréable d'avoir une analyse du code se rapprochant de la dissection des éléments HTML, ainsi que de la syntaxe de CSS (un peu plus loin dans le bouquin). Les informations essentielles sont détaillées et sont parfois même répétées au fur et à mesure de la lecture de l'ouvrage.

De quoi favoriser votre mémoire visuelle sans perturber pour autant les fanatiques du code.
Son nombre de pages (500), ne doit pas vous faire peur, puisque il est utile à la bonne présentation du contenu : ce bouquin reste très facile à lire.
Au sommaire
Le bouquin passe d'abord en revue les éléments HTML les plus utilisés, pour ensuite aborder les styles que l'on peut y appliquer, la partie CSS donc.
- Structure
- Texte
- Listes
- Liens
- Images
- Tableaux
- Formulaires
- Balisage autre
- Flash, vidéo et audio
- Introduction à CSS
- Couleur
- Texte
- Boîtes
- Listes, tableaux et formulaires
- Mise en page
- Images
- Mise en page HTML5
- Procédure et conception
- Informations pratiques
Des ressources en ligne (code des exemples, etc.) sont disponibles directement via le site de Pearson.
Retour de lecture
Mon avis est assez mitigé.

La mise en page du livre est vraiment au service de son contenu, c'est un point important et très agréable.
Au début de cet ouvrage l'auteur semble vouloir préter une attention particulière à l'accessibilité, notamment lorsqu'il aborde l'élément <img>. Cependant en allant plus loin dans l'ouvrage, on constate que pour lui l'élément <label> est optionnellement à associer à un champ de formulaire, l'attribut summary de <table> n'est jamais présenté et scope est souvent omis.
L'auteur annonce également à de nombreuses reprises des attributs ou éléments HTML comme étant dépréciés alors qu'ils ne le sont pas, et inversement.
J'ai fini par relever pas moins d'une quarantaine de coquilles, fautes dans le code, attributs mal écrits, erreurs dans les sélecteurs CSS, etc.
Le contenu de ce livre est donc à prendre avec des pincettes, et si des incohérences semblent vous sauter au visage, n'hésitez pas à consulter la documentation sur internet : une recherche Google devrait faire l'affaire.
Une fois arrivé à la fin de ma lecture, je me suis demandé : pourquoi aborder HTML5 et CSS3 si les bases ne sont pas suffisamment précises ?
La réponse est simple : ce bouquin a pour but la découverte des langages.
Ce livre s'adresse donc, d'après moi, principalement à deux cibles précises : les débutants qui souhaitent découvrir les langages HTML et CSS, ainsi que les éditeurs de contenu web qui souhaitent proposer une plus-value à leurs contenus en enrichissant leurs connaissances.
Dans tous les cas prenez un peu de recul après la lecture de ce bouquin, qui n'en reste pas moins un bon moyen de découvrir les langages HTML et CSS.
Vous connaissez certainement les Media Queries CSS. Celles-ci permettent d'adapter les instructions de style appliquées à un document HTML, en fonction de nombreux critères (résolution de l'écran, dimensions, périphérique de sortie). C'est la technique la plus souple et la plus utilisée actuellement pour ajuster dynamiquement l'affichage et obtenir un rendu graphique différent sur écrans classiques, mobiles, tablettes, et autres moyens d'accéder au web.
Avec matchMedia(), les mêmes capacités de détection sont rendues disponibles en JavaScript. La syntaxe de la requête média reste la même, ce qui est bien agréable. Ainsi, il sera possible de déclencher des actions complémentaires à ce que l'on peut déjà construire en CSS, que ce soit au chargement du document ou bien à n'importe quel moment à la demande en exécutant matchMedia().
C'est une méthode qui dépend de l'objet window (la fenêtre du navigateur) et qui prend en argument une chaîne de texte contenant l'expression à tester, pour retourner true ou false via sa propriété matches.
<script>
if (window.matchMedia("(min-width: 600px)").matches) {
/* La largeur minimum de l'affichage est 600 px inclus */
} else {
/* L'affichage est inférieur à 600px de large */
}
</script>
Si l'on examine de plus près l'objet retourné dans une console JavaScript...
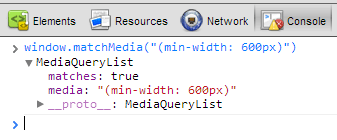
Celui-ci est de type MediaQueryList, et équipé de deux propriétés de base :
-
matches(booléentrue/falsequi permet de faire le test) -
media(la requête elle-même)
Bien sûr, cette méthode vient en complément de CSS et n'est pas vouée à remplacer les Media Queries là où elles sont déjà efficaces. Le but est de se brancher sur la gestion de la détection pour aller plus loin qu'une conséquence sur l'affichage des éléments.
// Fonction exécutée au redimensionnement
function redimensionnement() {
var result = document.getElementById('result');
if("matchMedia" in window) { // Détection
if(window.matchMedia("(min-width:600px)").matches) {
// Il y a de la place
} else {
// Il y en a moins...
}
}
}
// On lie l'événement resize à la fonction
window.addEventListener('resize', redimensionnement, false);
L'événement resize est tout indiqué pour déclencher une vérification avec matchMedia(). Consultez l'exemple suivant pour le voir en action.
Le dernier exemple va plus loin en chargeant des fichiers JavaScript selon le résultat renvoyé par matchMedia().
if(window.matchMedia("(min-width:800px)").matches) {
// Chargement de jQuery dans un nouvel élément <script> ajouté à la section <head>
var script1 = document.createElement('script');
script1.type='text/javascript';
script1.src = '//ajax.googleapis.com/ajax/libs/jquery/1.8.3/jquery.min.js';
script1.onload = function() {
// Lorsque jQuery est chargé...
// On fait la même chose : chargement dynamique // mais cette fois-ci avec jQuery (c'est plus simple)
$.getScript('slideshow.js');
}
// Insertion dans le DOM de la balise script initiale
document.getElementsByTagName('head')[0].appendChild(script1);
}
Il s'agit de faire appel à jQuery et un autre fichier de script conçu sur mesure pour lancer un slideshow si la largeur de l'affichage le permet.
Cette technique ici sert uniquement à la démonstration et exploite un script minimaliste pour sa compréhension. L'intérêt majeur serait de pouvoir détecter ce que l'on ne peut pas faire avec du JavaScript conventionnel, par exemple l'orientation (mentionnée précédemment) ou la densité de pixels pour charger des images appropriées : une démonstration est disponible sur Thinkmobilefirst : Conditional retina pictures loading.
Tableau des compatibilités
| Navigateurs | Versions |
|---|---|
|
|
Internet Explorer 10 |
|
|
Firefox 6 Firefox Android 15 |
|
|
Chrome 9 Chrome Mobile 18 (Android 4+) |
|
|
Opera 12.1 Opera Mobile 12.1 |
|
|
Safari 5.1 Safari Mobile 5.0 |
|
|
Android Browser 3.0 |
|
|
Blackberry Browser 10 |
Pour les anciens moteurs qui ne supporteraient pas nativement matchMedia, il existe des bibliothèques JavaScript, détectant (du mieux qu'elles peuvent) les changements d'état, notamment matchMedia.js développée par Paul Irish.
Les dispositifs mettant en exergue la sémantique qui permet notamment aux moteurs de recherche d'appréhender des informations précises sur le contenu d'une page Web ont été valorisés par l'avènement de la technologie Microdata dans HTML5. Fort des expérimentations en matière de balisage sémantique fournies par les microformats, on a pu mettre en place une syntaxe permettant de faciliter ce type de mise en évidence.

Trois attributs principaux sont utilisés à cet effet :
-
itemscope(signication : à quel champ sémantique correspond l'élément ?), -
itemtype(précise le type d'élément concerné), -
itemprop(les différentes propriétés, par exemple : le nom, la date, l'adresse, l'url…)
Ils sont complétés par itemref (permet de faire référence à un type déjà défini dans la page) et itemid (fait référence à une clé unique, reconnue de façon quasi-universelle).
Pour compléter ces attributs, tout se joue autour de la définition d'un vocabulaire spécifique à chaque type d'identification (personne, évènement, lieu,…). Et à ce petit jeu-là, schema.org est une référence en la matière, initiative commune de Google, Yahoo, Bing et Yandex décidée en 2011.

Voici un petit tour d'horizon des différents types et propriétés fournis par cette organisation. Mais avant cela, un petit rappel ou un éclaircissement pour ceux qui ne connaîtraient pas les Microdatas.
Comment inclure des Microdatas ?
A la fin du tutoriel sur les Microformats, nous faisions une petite référence aux Microdatas, nous y parlions notamment des quatre attributs mentionnés plus haut. L'ensemble de ces attributs apporte des informations hiérarchiquement structurées.
-
itemscopeetitemtype -
Ils s'utilisent conjointement dans une balise délimitant le pan d'informations qui sera affublé d'éléments sémantiques.
itemscopeindique simplement que les informations contenues dans la balise ont été enrichies etitemtypeindique à quel type de données nous avons à faire. Exemple :
Dans cet exemple, on donne l'étendue des informations microformatées (<article itemscope itemtype="http://schema.org/Article"> <!-- Les données formatées concernant l'article (titre, auteur, permalien…) --> </article>itemscope) et le type d'élément auquel ils se réfèrent, ici, un article (itemtype). -
itemprop -
Permet d'indiquer à quoi correspondent les différentes informations. En reprenant l'exemple d'avant on peut obtenir ceci :
<article itemscope itemtype="http://schema.org/Article"> <header> <h1 itemprop="name">Microformats versus Microdatas</h1> <ul> <li>Le <time itemprop="dateCreated" datetime="2012-11-20T20:00">20 novembre 2012</time> par <span itemprop="creator">Jojaba</span></li> <li>Permalien : <a href="http://lien_vers_article.html" itemprop="url">Microformats versus Microdatas</a></li> <ul> </header> <section itemprop="text"> <p> Les Microdatas sont relativement récents, puisque apparus avec HTML5 alors que les microformats sont bien plus anciens (le premier µF fait son apparition en 2003), ce qui leur donne des atouts majeurs : ils ont pu être éprouvés, ils ont évolué, ils ont été pris en compte par bon nombre d'acteurs sur le Web (voir à ce sujet <a href="http://tantek.com/presentations/2012/07/html5">la diapo de Tantek Çelik</a>… Pour autant, il ne faut surtout pas négliger les Microdatas qui sont LA solution d'avenir. D'ailleurs, ils sont directements inspirés des Microformats. D'autre part, ils sont beaucoup plus adaptés aux différentes situations que l'on peut rencontrer grâce au vocabulaire fournit par schema.org. Leur seul défaut étant qu'ils ne sont utilisables qu'avec HTML5… <p> <p> Conclusion : je dirais que les microformats peuvent encore être utiles pour des pages qui ne sont pas codées en HTML5 et que microdata devrait être utilisé le plus possible (d'aileurs, ils sont <a href="http://support.google.com/webmasters/bin/answer.py?hl=fr&answer=99170&topic=1088472&ctx=topic">recommandés par Google</a>). </p> </section> </article>-
itemprop="name": indique le nom de l'article dans ce cas de figure mais pourrait également indiquer le nom d'une personne si on est dans le cas de l'identification de personne. -
itemprop="dateCreated" datetime="2012-11-20T20:00": date de création de l'article. dans l'attributdatetimeon place la date au format ISO 8601 -
itemprop="creator": l'auteur de l'article. -
itemprop="text": le contenu de l'article.
-
-
itemref -
Cet attribut permet de reprendre des informations déjà présentes sur la même page en indiquant l'id de la partie enrichie sémantiquement. Par exemple :
itemref="titre emplacement"inclura les éléments ayant comme id titre et emplacement.
Éléments imbriqués
Il peut arriver qu'une propriété soit elle-même définie par d'autres propriétés et donc être considérée comme étant un type d'élément. Elle sera donc imbriquée dans type parent. Petit exemple pour comprendre :
<article itemscope itemtype="http://schema.org/Event">
<hgroup>
<h1 itemprop="name">Kiwiparty 2051</h1>
<p>Proposée par <span itemprop="attendee" itemscope itemtype="http://schema.org/Person"><span itemprop="name">Raphaël</span> et <span itemprop="colleague">Rodolphe</span> - <span itemprop="affiliation">Alsacréations</span></span></p>
</hgroup>
<section itemprop="description">
<p>Cette 52e édition vous permettra de découvrir les nouvelles balises HTML 13, La spécification CSS 9.2.a et bien d'autres nouveautés. Venez nombreux !</p>
</section>
<footer>Lieu : <span itemprop="location">Epitech</span> | Date : <time itemprop="startDate" datetime="2051-04-01T09:00">1er avril 2051 à 9h00</footer>
</article>
Le type imbriqué (Person) a été mis en gras dans l'exemple ci-dessus.
Les différents itemtype disponibles sur schema.org

Vous l'aurez compris, tout se joue au niveau du vocabulaire utilisé. Plus il est riche, plus il est précis et plus vous pourrez donner du sens à votre contenu. Schema.org propose une hiérarchie assez conséquente, touchant à bon nombre de domaines, jugez-en plutôt vous-même : Toute l'arborescence des types définis par schema.org. Le principe est simple : plus vous descendez dans l'arborescence (parent » fils), plus le vocabulaire se précisera. Le parent "racine" Thing est défini par quelques propriétés de sens assez large (additionalType, description, image, name, url) puisqu'il devrait pouvoir s'appliquer à tout type d'élément. Au fur et à mesure de la progression dans la hiérarchie (vers le bas) vous constaterez que les propriétés définissent une sémantique de plus en plus pointue. Par exemple, Thing » CreativeWork » Article est affublé de 3 propriétés : articleBody, articleSection, wordCount.
Héritage
Un autre point intéressant dans l'utilisation des éléments hiérarchiques définis par schema.org est que chaque fils hérite des propriétés de son (ses) parent(s). En reprenant l'exemple précédent, le type Article a donc comme propriétés spécifiques articleBody, articleSection, wordCount, mais également toutes les propriétés du niveau supérieur c'est à dire celles de CreativeWork (about, accountablePerson, aggregateRating, alternativeHeadline, associatedMedia, audience, audio, author, award, awards, comment, contentLocation, contentRating, contributor, copyrightHolder, copyrightYear, creator, dateCreated, dateModified, datePublished, discussionUrl, editor, encoding, encodings, genre, headline, inLanguage, interactionCount, isFamilyFriendly, keywords, mentions, offers, provider, publisher, publishingPrinciples, review, reviews, sourceOrganization, text, thumbnailUrl, version, video) et de Thing (additionalType, description, image, name, url).

Vous pouvez constater cet état de fait dans la référence du schéma Article sur le site de schema.org.
Conseils pour l'ajout de balises sémantiques schema.org
- Première règle : plus il y en a, mieux c'est. Il faut néanmoins garder à l'esprit que seul le contenu visible par les utilisateurs (nous rappelons qu'à la base, c'est pour eux que cet effort est fait) devrait être enrichi.
-
Vous constaterez dans la spécification des différents types que l'on défini la valeur attendue pour chaque propriété. Cette valeur peut être un élément imbriqué (exemple : pour
CreativeWork, on précise que la propriétéauthordevrait être du typeOrganizationouPerson). Or ceci n'est pas une obligation, vous pouvez également utiliser du texte normal ou une URL à la place de ces sous-types. Il est également possible d'utiliser un enfant du type recommandé, par exemple, si la valeur attendue est de typePlace, vous pouvez utiliser à la placeLocalBusiness. -
Enfin, les informations fournies peuvent être indiquées de façon à être interprétables par les machines.
-
Les dates et heures doivent être utilisées dans des balises
<time>, insérées dans l'attributdatetime.
 Dates et horaires pour machines sur schema.org
Dates et horaires pour machines sur schema.org -
Il est consillé d'utiliser la balise
<link>pour les propriéés n'ayant que peu de valeurs ou pour des références canoniques.
Références canoniques sur schema.org -
Il peut arriver qu'une information sur la page Web ayant un fort potentiel sémantique ne puisse pas être marquée parce qu'elle se trouve au mauvais endroit. Dans ce cas, il est recommandé d'utiliser la balise
<meta>et l'attributcontentà cet effet.
Utilisation de <meta>sur schema.org
-
Les dates et heures doivent être utilisées dans des balises
Conclusion
Schema.org démontre une grande souplesse d'utilisation, de nombreux vocabulaires adaptés à beaucoup de situations, c'est également une de ses forces : cela facilite l'implémentation de contenu sémantique par le développeur. En outre :
Search engines including Bing, Google, Yahoo! and Yandex rely on this markup to improve the display of search results, making it easier for people to find the right web pages.
Les moteurs de recherche majeurs prennent en charge le vocabulaire schema.org pour l'affichage de résultats de recherche. Tout est là pour faire de la sémantique une plus-value indéniable de nos sites !
Ressources
- Sur le site officiel (en anglais donc) : page à partir de laquelle a été réalisé ce tutoriel
- L'outil de test Google pour données structurées (en anglais)
- La liste des types schema.org au format PDF (65,5 Ko) et PNG (490 Ko)
- Quiz sur les microformats
{kind=link}
Sous-titré "Le guide de survie de l'intégrateur !" et préfacé par les experts de Temesis Elie Sloïm et Laurent Denis, le livre "Intégration web - les bonnes pratiques" est, comme son nom l'indique, un condensé de méthodologies destiné aux de l'intégrateur HTML et CSS voire plus généralement aux développeurs web front-end.
Avis personnel :
Corinne Schillinger signe un ouvrage très complet que j'attendais avec impatience depuis longtemps. Un livre en français, entièrement dédié à l'intégration web on n'en voit pas si souvent... D'autant plus que nous sommes chanceux : le livre est très bon !
Divisé en quatre grandes parties, il recense les bonnes pratiques de la création d'un site web afin de le rendre accessible, fonctionnel et respectueux des standards du web. Presque chaque paragraphe est ponctué d'un lien permettant d'en apprendre davantage sur le thème abordé, ce qui est un véritable plus permettant de vérifier l'information et de la compléter si nécessaire.
En clair, tout y est : checklists de qualité, compatibilité entre les navigateurs, HTML5 et sémantique, rôles ARIA, frameworks et préprocesseurs CSS, feuilles de styles, compression des images pour le web, accessibilité... Je n'ai pas encore trouvé un livre semblable, traitant de ce sujet de manière aussi pertinente et intéressante !
Attention tout de même : comme indiqué dans l'avant-propos, le livre n'est pas destiné aux débutants qui "souhaitent décrouvrir les joies du code". Par contre, si comme moi vous êtes à l'aise avec les langages HTML et CSS, que vous êtes rigoureux dans l'écriture du code et que vous êtes sensible au respect des normes et aux rêgles d'accessibilité sans trop savoir par où commencer, foncez, ce livre est fait pour vous !
Sommaire :
-
Bien préparer son projet
Organiser son espace de travail, S'équiper des bons outils, Mettre en place l'environnement de test -
Élaborer un socle HTML solide
Adopter HTML5, Concevoir les fondations, Construire la structure, Injecter le contenu, Incorporer les images -
Habiller le contenu grâce aux CSS
Réviser les bases, Définir une convention d'écriture, Organiser le code CSS, Prendre connaissance des facteurs d'optimisation, Contrôler et déboguer, Préparer la livraison (ou la mise en ligne) - Peaufiner les détails
Comme promis, une nouvelle Opération Kiwiz commence dès aujourd'hui ! Notre partenaire Eyrolles va permettre à tous les heureux possesseurs de Kiwiz de les échanger contre des ouvrages informatiques de référence.

Les Kiwiz, c'est quoi déjà ?
Les Kiwiz représentent une sorte de cagnotte que chaque membre peut créditer ou débiter.
Pour en savoir plus, parcourez la page Kiwiz d'Alsacréations. Pour connaître le nombre de Kiwiz en votre possession, faites un tour sur votre profil.

Comment gagner des Kiwiz ?
Sommairement, on gagne des Kiwiz en participant aux concours, en publiant des actualités, des astuces ou tutoriels. Vous trouverez le barème des gains détaillé sur votre page Kiwiz.
En règle générale, nous sommes friands de tous les articles ayant trait aux domaines des Standards web et plus généralement les thèmes autour des standards, de HTML5, CSS3, le Webdesign, les gestionnaires de contenu (CMS), l'accessibilité numérique, jQuery, AJAX et le Web mobile.
N'hésitez pas à visiter la page procédure de proposition d'articles et tutoriels.
Pour rappel, ce n'est pas grave si vous ne disposez pas suffisamment de Kiwiz pour cette session : rien de vous empêche de les accumuler pour l'une des prochaines opérations.
Comment profiter de cette opération Kiwiz ?
Pendant environ deux semaines (fin de l'opération le vendredi 30 novembre 2012), vous allez pouvoir échanger vos Kiwiz contre des livres informatique des éditions Eyrolles, selon le barème de gains suivant :
- 50 kiwiz échangeables contre un ouvrage dont le prix peut être supérieur 40€
- 40 kiwiz échangeables contre un ouvrage dont le prix peut être au maximum compris entre 30€ et 40€
- 30 kiwiz échangeables contre un ouvrage dont le prix peut être au maximum compris entre 20€ et 30€
- 20 kiwiz échangeables contre un ouvrage dont le prix est inférieur à 20€
Modalités de l'opération
- Il faut avoir un crédit positif de Kiwiz sur son compte (vous pouvez en gagner pendant toute la durée de l'opération et même après),
- L'ouvrage devra faire partie de la rubrique informatique (ou logiciels Image et Son) à l'exception du livre Collector "Tatoo Portraits",
- L'opération est limitée dans le temps : fin de l'opération le 30 novembre 2012,
- On ne pourra puiser que dans les ouvrages récents (parus depuis 2007),
- Les ouvrages sont à choisir sur www.editions-eyrolles.com (ceci pour éviter toute confusion avec un livre en vente sur eyrolles.com qui serait publié chez un autre éditeur).
- L'échange est limité à 2 livres maximum par personne pour chaque opération.
Je récolterai les coordonnées et choix des bénéficiaires à la fin du mois et les transmettrai à Eyrolles pour l'envoi des livres. Il vous suffit de m'envoyer un Message Privé avec vos choix d'ouvrages, votre nom et vos coordonnées postales complètes.
Encore un grand merci à Eyrolles, toujours partant pour nos différents projets !
MobileHTML est un tableau de compatibilité récapitulatif à destination des plate-formes mobiles. On y retrouve le niveau de prise en charge des fonctionnalités HTML5 mais aussi CSS3 et API variées. Les versions testées sont un peu plus détaillées que sur le fameux site Caniuse.com.
Dans la même lignée que "Typo & Web" précédemment évoqué, "Webgrids" traite - en résumé - de la mise en page web.
Plus en détail, le sous-titre est révélateur : "Structure et typographie de la page web". L'ouvrage revient aux fondamentaux de la mise en page, à ses racines historiques et culturelles dans le but de faire des parallèles évocateurs. La structure d'un document est abordée de manière complète, et les enjeux sont expliqués clairement et illustrés.
Le livre traite de tous les types de grilles : les règles imposées et comment les enfreindre, l'importance du rythme vertical, les à-priori et l'ordre établi qui règnent déjà sur un support pourtant bien jeune. Mais il y est également question de composition, des bonnes pratiques et des parti-pris potentiels, le tout de manière documentéé, illustrée et commentée.
C'est un ouvrage qui permet de conscientiser et théoriser les possibilités de composition, de structure et de typographie disponibles sur le web - et permet de réaliser qu'en définitive le web n'est pas aussi limité qu'on l'eût cru. Il s'adresse d'aileurs autant aux intégrateurs qu'aux graphistes et webdesigners.
Sommaire
- Introduction
-
SPÉCIFICITÉS DU SUPPORT
S'affranchir de l'héritage du papier
Approche du support et accessibilité -
LA GRILLE, MATRICE DE LA PAGE
L'importance des marges
Types de grilles et emplois
La ligne de base
Outils de construction
La grille, un frein à la créativité ? -
AGENCER LES BLOCS DANS LA GRILLE
Intelligibilité, lisibilité, communication
Lier, hiérarchiser, séparer
Stabilité et dynamisme : histoire de deux tendances
Organisation des masses visuelles -
COMPOSITION DU TEXTE COURANT
La lecture sur écran
Le paragraphe
Ponctuer le texte pour le rendre plus digeste
Ne pas oublier les règles typographiques - Conclusion
Présentation
Qualité Web, le livre, est sorti il y a quelques jours. Les plus impatients ont pu le pré-commander avant sa sortie, le 15 Octobre 2012.
Co-écrit par Élie Sloïm, Muriel de Dona, Laurent Denis et Fabrice Bonny, le livre, comme son nom l'indique, aborde la qualité Web de manière globale via le projet Opquast (pour OPen QUAlity STandards, pour ceux qui l'ignoreraient).
Voici le sommaire complet :
- Préambule
- Bonnes pratiques : 217 fiches - Alternatives - Code - Contact - Contenus - E-Commerce - Espaces publics - Fichiers & Multime?dia - Formulaires - Hyperliens - Identification - Internationalisation - Navigation - Newsletter - Pre?sentation - Serveur & Performances - Syndication - Se?curite? & Confidentialite? - Tableaux
- La qualité Web - De?finition - Un mode?le pour la qualite? web : VPTCS - Traduire le mode?le sur le terrain - De l’artisanal a? l’industriel
- Audit d’un site web en ligne - Audit rapide et audit expert - Prise en main - Echantillonnage - Evaluation - Rapport d’audit
- Audit en cours de production - Prototypage, wireframing - Cre?ation graphique - Inte?gration XHTML/CSS - De?veloppements - Aspects e?ditoriaux
- Consolider le cahier des charges - Un cahier des charges, dans quel but ? Interface, visibilite? et aspects techniques - Fixer des objectifs qualite? et les inte?grer au cahier des charges
- Piloter et ame?liorer la qualite? d’un parc de sites - Quel re?fe?rentiel pour quel retour sur investissement ? - Quelle approche choisir ? - Quels indicateurs ?
- Un re?fe?rentiel, des usages - Choix et de?ploiement d’un CMS - Formation - Auto-de?claration, labellisation, certification
- Check-lists en suivi de production
- Check-lists SEO & OpenData
- Trousse a? outils
- Glossaire
- Index
Si on résume un peu, le livre se compose en fait de trois grandes parties :
- les fiches des 217 bonnes pratiques (une fiche pour chacune),
- l'explication de la qualité Web : comment la gérer, les audits, etc.,
- et les annexes : les check-lists, savoir quand les appliquer selon le stade du projet, etc.
Avis (personnel)
Même si le livre peut paraitre conséquent (presque 400 pages et 1 kilo !), il se lit très bien, l'idée d'une fiche par bonne pratique permet une consultation agréable, c'est clair et aéré, et surtout il est aisé d'y revenir en cas de besoin.
Que ce soit le gestionnaire de la qualité, le décideur, le technicien soucieux de bien faire ou le débutant qui découvre ces concepts, tous trouveront dans ce livre une mine d'informations utiles à garder à l'esprit pour créer des sites… de qualité !
Le ton se veut résolument pragmatique et professionnel, l'expérience des auteurs se ressent clairement à travers les avis, les conseils et les remarques.
Autres informations
Caractéristiques
- Parution le 15 octobre 2012
- 392 pages
- Format : 16,5 x 24 cm
- Poids : 900 g
- ISBN : 978-2-9543031-0-9
À noter, le livre est préfacé par Amélie Boucher et Stéphane Deschamps.
Le web d’aujourd’hui est en train d’être conquis par nos amis les appareils mobiles et plus précisément les smartphones et les tablettes. Or ces terminaux possèdent quelque chose que très peu de nos chers ordinateurs fixes ont : un accéléromètre. Ce petit composant permet de connaître l’inclinaison presque exacte de l’appareil dans l’espace, c’est à dire sur trois axes x, y et z et l'accélération subite par l'appareil sur ces mêmes axes.
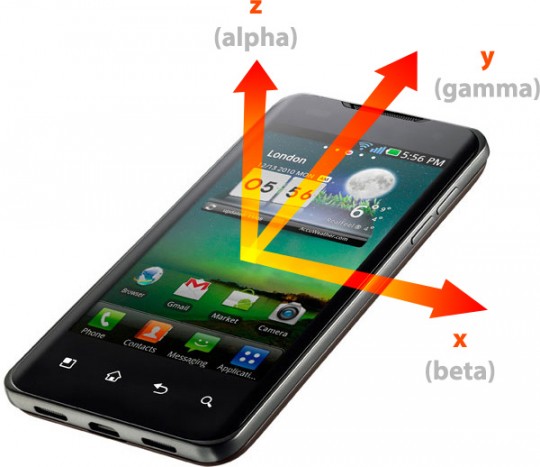
Avec l’arrivée de HTML5, une flopée de nouvelle API JavaScript ont fait leur apparition, dont la Device Orientation API et la Device Motion API.
Device Orientation API
C’est avec cette API que l’on va pouvoir collecter les données d'inclinaison envoyées par l’accéléromètre pour ensuite les utiliser dans diverses applications. Lançons nous sans plus attendre dans le code !
Tout d’abord, nous allons faire une page toute simple avec juste un élément div :
<!DOCTYPE html>
<html>
<head>
<meta charset = "utf-8" />
<title>Device Orientation API</title>
</head>
<body>
<div id="log"></div>
</body>
</html>
Passons maintenant au code JavaScript. Une fonction sera lancée lorsque l’événement deviceorientation sera déclenché, appelant une fonction de callback nommée process. La méthode addEventListener permet d'attacher cette fonction appelée en retour, à l'événement deviceorientation. Attention, elle n'est pas disponible sur les anciens moteurs d'Internet Explorer jusqu'à la version 8 incluse (il faudra dans ce cas se pencher vers attachEvent ou passer par un framework JavaScript simplifiant les appels).
if(window.DeviceOrientationEvent) {
window.addEventListener("deviceorientation", process, false);
} else {
// Le navigateur ne supporte pas l'événement deviceorientation
}
Cette fonction va récupérer les valeur alpha, beta et gamma et va les afficher dans l'élément div pour avoir un retour sur le document. Ces valeurs sont stockées dans l'objet event récupéré par la fonction de callback.
function process(event) {
var alpha = event.alpha;
var beta = event.beta;
var gamma = event.gamma;
document.getElementById("log").innerHTML = "<ul><li>Alpha : " + alpha + "</li><li>Beta : " + beta + "</li><li>Gamma : " + gamma + "</li></ul>";
}
Mais attendez ! Je ne vous ai même pas défini alpha beta et gamma :
-
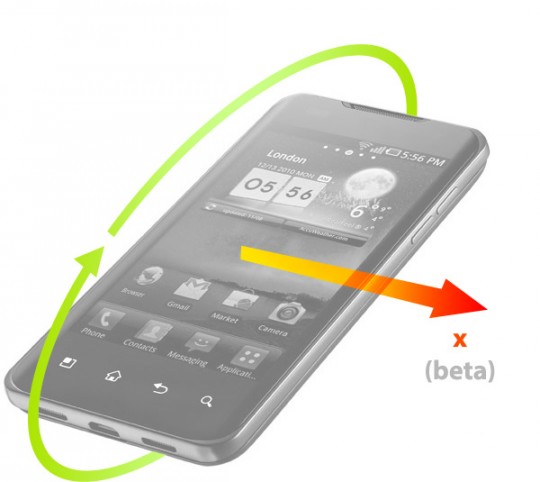
alpha représente l’angle de rotation (en degrés) autour de l’axe Z
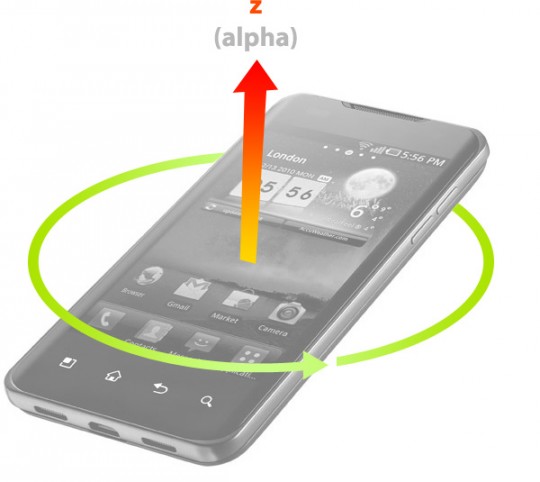
-
beta représente l’angle d’inclinaison (en degrés) autour de l’axe X
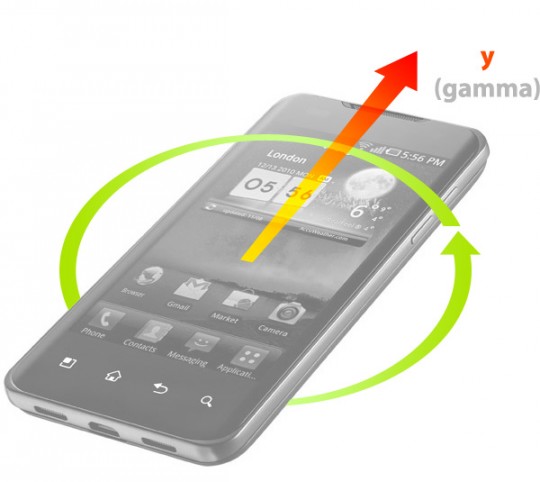
-
gamma représente l’angle d’inclinaison (en degrés) autour de l’axe Y
Toutes ces valeurs sont théoriquement à 0 lorsque l’appareil est posé à plat et qu'il n'a pas bougé depuis le chargement de la page. Par contre, tout dépend du matériel : un détecteur un peu sensible pourra constamment signaler des valeurs changeantes alors même que le mobile est immobile. Il faudra alors prendre le relais sur les valeurs renvoyées pour ignorer les plus infimes variations ou les arrondir.
Notre script est complet en fonctionnel. Le voilà en action :
Vous remarquerez qu’il y a beaucoup de chiffres après la virgule. Dans certains cas, il est préférable d’arrondir ces valeurs à l’aide de Math.round(), comme par exemple lorsqu’on veut faire bouger un bloc en fonction de l’orientation de l’appareil. Dans ce cas, si les valeurs ne sont pas arrondies, on peut observer un tremblement du bloc en question dû aux valeurs de alpha, beta et gamma qui changent constamment.
Device Motion API
L'API Device Motion ne retourne pas de valeurs d'angles mais d'accélération en mètres par seconde au carré (m/s²), sur les trois axes x, y et z. Son usage est semblable celui de l'Orientation.
Appelons à nouveau notre fonction callback mais cette fois lorsque l'évènement devicemotion est déclenché.
if(window.DeviceMotionEvent) {
window.addEventListener("devicemotion", process, false);
} else {
// Le navigateur ne supporte pas l'événement devicemotion
}
Déclarons ensuite notre fonction callback qui affichera les valeurs d'accélération dans notre div.
function process(event) {
var x = event.accelerationIncludingGravity.x;
var y = event.accelerationIncludingGravity.y;
var z = event.accelerationIncludingGravity.z;
document.getElementById("log").innerHTML = "<ul><li>X : " + x + "</li><li>Y : " + y + "</li><li>Z : " + z + "</li></ul>";
}
L'objet event retourne deux propriétés :
-
acceleration: L'accélération calculée par l'appareil en enlevant la gravité. -
accelerationIncludingGravity: La valeur de l'accélération brute, retournée par l'accéléromètre.
Ainsi, lorsque l'appareil est posé à plat et ne bouge pas, on obtiendra théoriquement :
-
Avec
acceleration:{0,0,0} -
Avec
accelerationIncludingGravity:{0,0,9.81}
Ici 9.81 correspond à la valeur de la pesanteur en gravité terrestre. Il est recommandé d'utiliser accelerationIncludingGravity car certains appareils ne peuvent pas calculer une accélération en y soustrayant la gravité, et on obtiendrait alors avec acceleration les mêmes valeurs qu'avec accelerationIncludingGravity.
Encore une fois, vous remarquerez que les valeurs changent tout le temps, même lorsque l'appareil est immobile, ceci à cause de la précision variable de l'accéléromètre.
Conclusion
Voilà donc deux API très utiles pour développer des jeux pour mobiles (avec canvas notamment), ou créer une interaction supplémentaire avec le document, par exemple un effet parallaxe en fonction de l'inclinaison de l'appareil.
Ressources utiles
Estelle Weyl est une auteure reconnue dans le domaine du Web, ayant en particulier signé les ouvrages "HTML5, the Definitive Guide", et "Mobile HTML5", publiés chez o'Reilly, ou encore "HTML5 and CSS3 for the Real World" chez SitePoint. Développeur professionnel, précédement consultante pour Apple et Yahoo, Elle aime partager son savoir et son expérience lors de conférences qu'elle donne tout autour du monde, et sur son blog Standardista qui compile de nombreux trucs et astuces.
Estelle anime également des formations, et la prochaine aura lieu en marge de son passage à Paris pour la conférence JS.everywhere() Europe. En effet le 15 novembre prochain, elle animera un atelier pratique sur le CSS3, s'adressant à des développeurs expérimentés, connaissant déjà les CSS, ou ayant abordé les CSS3, et désireux d'acquérir un niveau avancé.
La formation aura lieu dans les locaux de Supinfo, 23 rue du Château Landon, 75010 Paris de 9h30 à 17h30. Plus d'information sur http://jseverywhere.eu/workshops/
Des attestations de formation pourront être délivrées pour vos dossiers de prise en charge.
Le coût de la journée, incluant le repas, est de 249€ TTC. Un coupon de réduction de 50€ est cependant disponible avec le code "alsa" sur http://cssninja.eventbrite.fr/?discount=alsa (nombre de places limité)