Alsacreations.com - Actualités - Archives (octobre 2024)
Les dernières actualités d'Alsacreations.com
Les import maps sont une fonctionnalité moderne de JavaScript qui permet de contrôler comment le navigateur résout les imports de modules.
Vous avez sûrement déjà rencontré dans vos projets des modules JavaScript, aussi appelés ESM (EcmaScript Modules) qui induisent un découpage des portions de code et de données. C'est très pratique, avec certains fichiers - en général fournis par une bibliothèque - qui exportent des fonctions, tableaux, objets, etc. pour les mettre à la disposition d'autres fichiers - en général les vôtres - qui les importent.
On sait aussi que depuis quelques années de tels scripts peuvent être chargés dans le navigateur à l'aide de la balise script équipée de l'attribut type="module".
Que sont les import maps ?
Une déclaration d'import map pourrait être la suivante à l'aide de la nouvelle valeur type="importmap".
<script type="importmap">
{
"imports": {
"logger": "/js/logger.js",
"tools/": "/js/tools/",
"lodash": "https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"
}
}
</script>
On peut constater qu'il s'agit d'un objet, contenant une clé "imports", elle même définissant une correspondance entre des noms courts et des chemins longs.
On peut aussi faire appel à un beau fichier JSON contenant cette "carte", ce qui semblera plus propre que de les déclarer inline dans le corps de la page.
<script type="importmap" src="map.json">
Avantages
Cela a pour but de :
- Simplifier la gestion des dépendances dans le navigateur.
- Permettre d'utiliser des noms simples plutôt que des chemins complets.
- Éviter d'avoir à spécifier les versions dans chaque import.
Ainsi on pourra écrire ensuite
import _ from 'lodash';
// Import depuis un chemin local
import { log } from 'logger';
// Import via un préfixe
import { maFonction } from 'tools/malib.js';
On améliore la lisibilité et on peut plus facilement changer les versions et les chemins réels vers les dépendances.
Il y a quelques petites limitations : les projets d'envergure avec des frameworks et des outils de compilation tels que Vite, viennent déjà avec des solutions de résolution de modules. Certaines fonctionnalités qui optimisent le développement et le poids des ressources (hot reloading, tree shaking) ne sont pas disponibles. C'est pourquoi on s'en servira plutôt pour du prototypage rapide, des petites démonstrations techniques ou des projets qui ne passent pas par des frameworks évolués.
L'attribut type="importmap" est supporté par tous les navigateurs actuels est considéré comme faisant partie de la baseline 2023.
Mermaid est un langage qui permet de créer des diagrammes dynamiques directement dans des fichiers Markdown c'est à dire en mode texte.
Il est très utile pour représenter visuellement des concepts complexes sous forme de graphiques, schémas, diagrammes (comme des diagrammes de flux, des organigrammes, des graphiques Gantt, etc.) dans un format simple et lisible.
Un beau schéma vaut mille mots de markdown.
Mermaid s'intègre directement avec des plateformes et outils de documentation comme GitHub, GitLab, Docusaurus, MkDocs, ou Jekyll. Ainsi on peut inclure des diagrammes légers dans des fichiers README ou des wikis sans avoir besoin de les exporter en images.... images qui seront souvent non modifiables par les autres personnes participant à un projet car elles n'auront pas les sources tandis qu'avec Mermaid la source de l'image sera dans le document.
Le résultat étant généré à la volée en SVG (vectoriel) il s'adaptera à la résolution sans difficulté ainsi qu'à la préférence de thème, clair ou sombre (dark mode).
Exemples
La syntaxe de mermaid est assez basique, mais efficace.
graph TD;
A-->B;
A-->C;
B-->D;
C-->D;
La première ligne définit le type de diagramme et les suivantes la logique que l'on souhaite écrire. Remarquez qu'il n'y a pas d'instruction de positionnement de bloc, on s'attache juste à décrire les relations, et la bibliothèque JavaScript se charge du reste en transformant ce texte en un beau schéma.
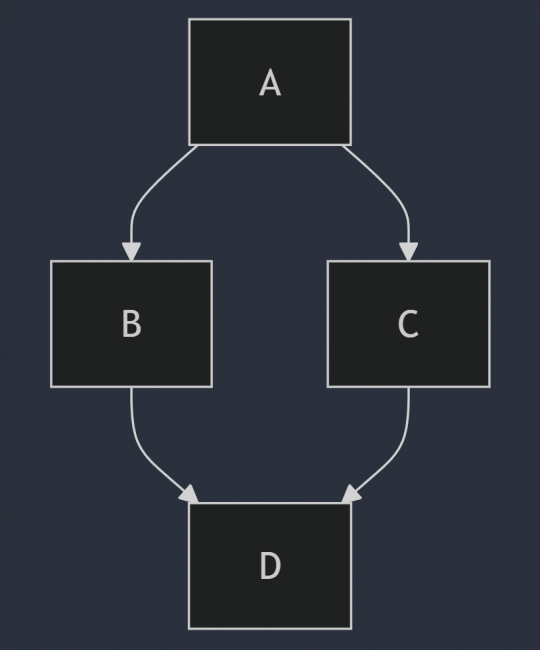
On peut même générer des flux Git. ð¤
gitGraph
commit
commit
branch develop
checkout develop
commit
commit
checkout main
merge develop
commit
commit
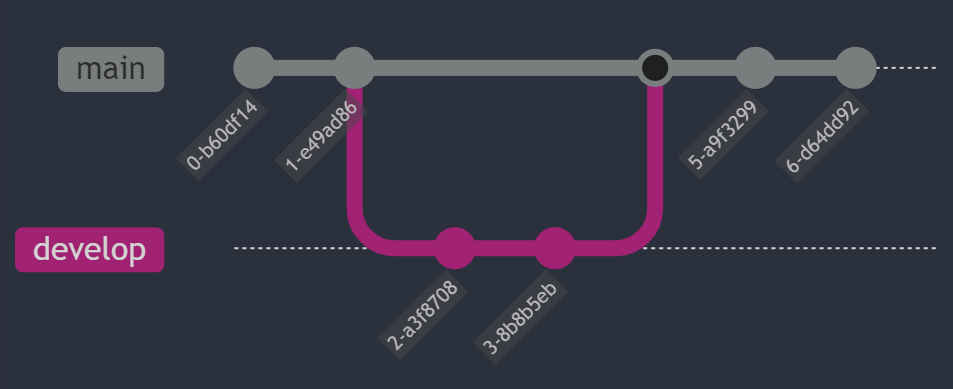
Voici un diagramme de séquence bien complexe à dessiner, et pourtant simple à écrire en texte.
sequenceDiagram
Gitlab->>Gitlab: reçoit un Push sur main
Gitlab->>Runner: Lance un runner
Runner->>Serveur: Connexion SSH
Runner->>Serveur: Envoie les instructions shell du job
Serveur-->>Gitlab: Connexion SSH vers Gitlab
Serveur-->>Gitlab: git pull
Gitlab-->>Serveur: Fichiers
Runner->>Gitlab: Retourne les logs
Note over Runner, Serveur: Fin
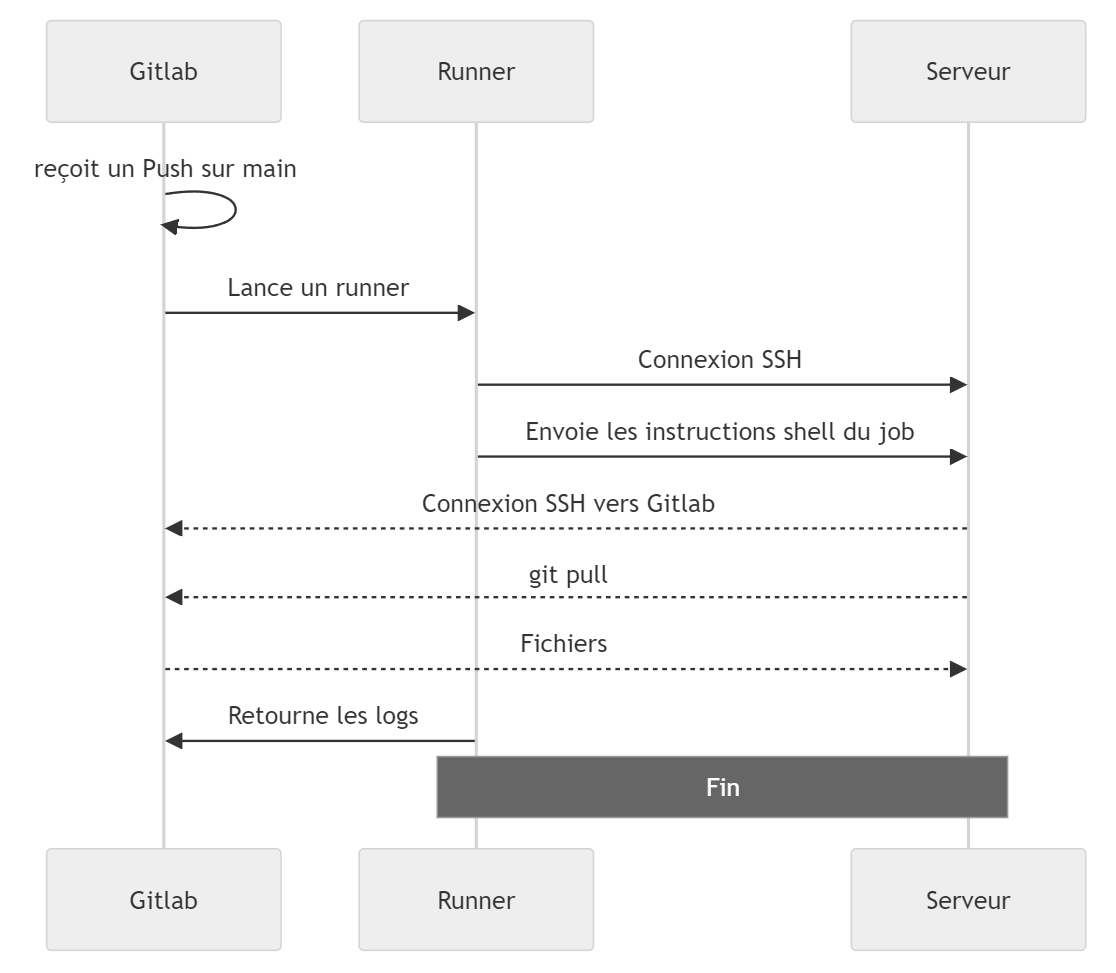
Voici le rendu sur GitHub avec en bonus quelques boutons pour zoomer, se déplacer, copier, etc.
Avantages
- C'est du texte.
- C'est modifiable.
- C'est versionnable.
- C'est adapté aux wikis.
- C'est multi-plateforme.
- C'est compris par GitHub et GitLab.
Inconvénients
- Il faut a priori connaître sa syntaxe (encore une autre...) (mais... des outils existent)
Support par GitHub et GitLab
Les deux plateformes les plus répandues de versionnement de code source supportent nativement Mermaid, ce qui est un grand avantage pour documenter vos projets, vos fichiers README.md de manière compréhensible et remplacer de longues explications de texte par des schémas limpides.
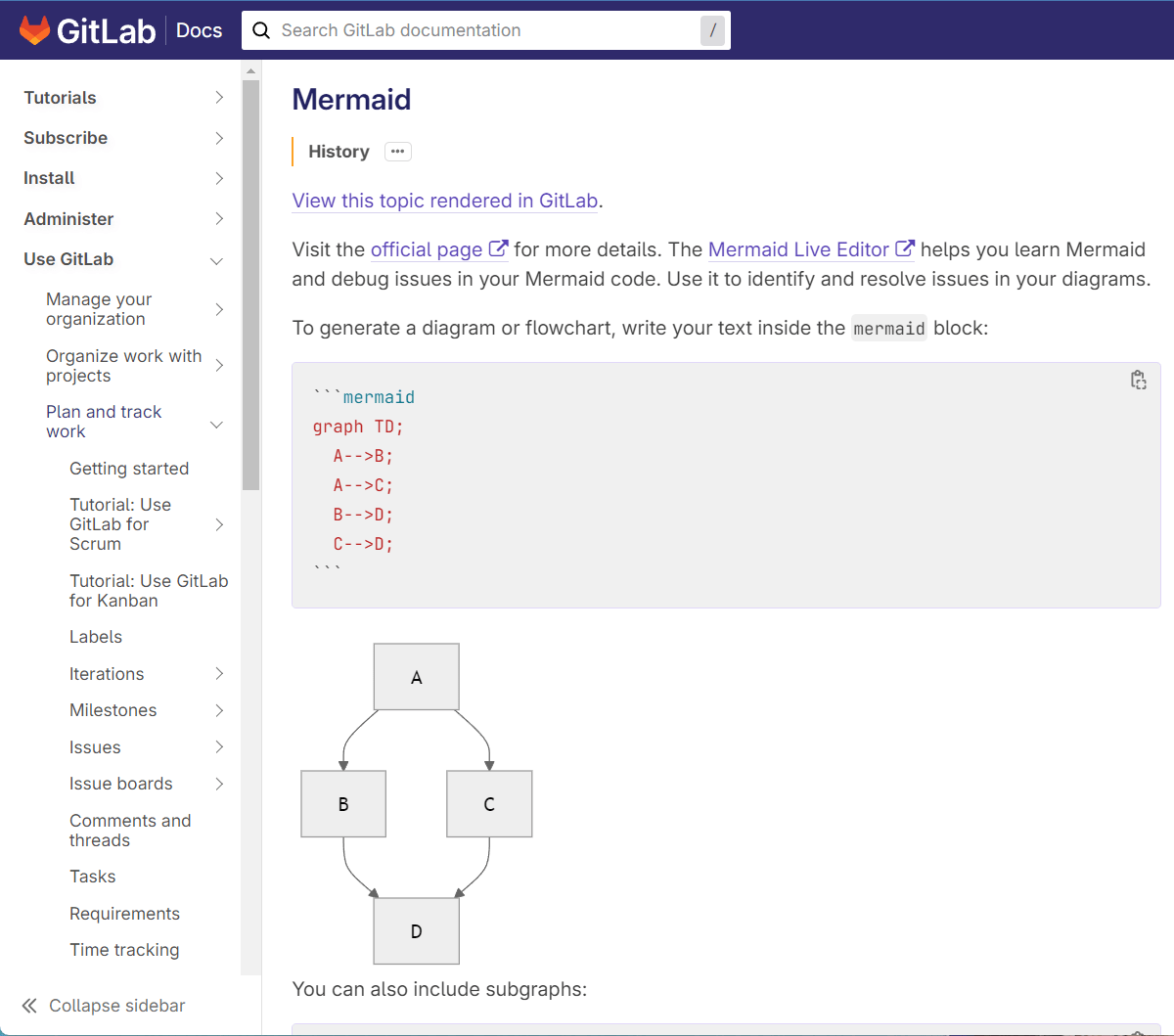
Documentation officielle
La documentation de Mermaid est très bien conçue et vous permet rapidement de cerner tout ce que permet la bibliothèque
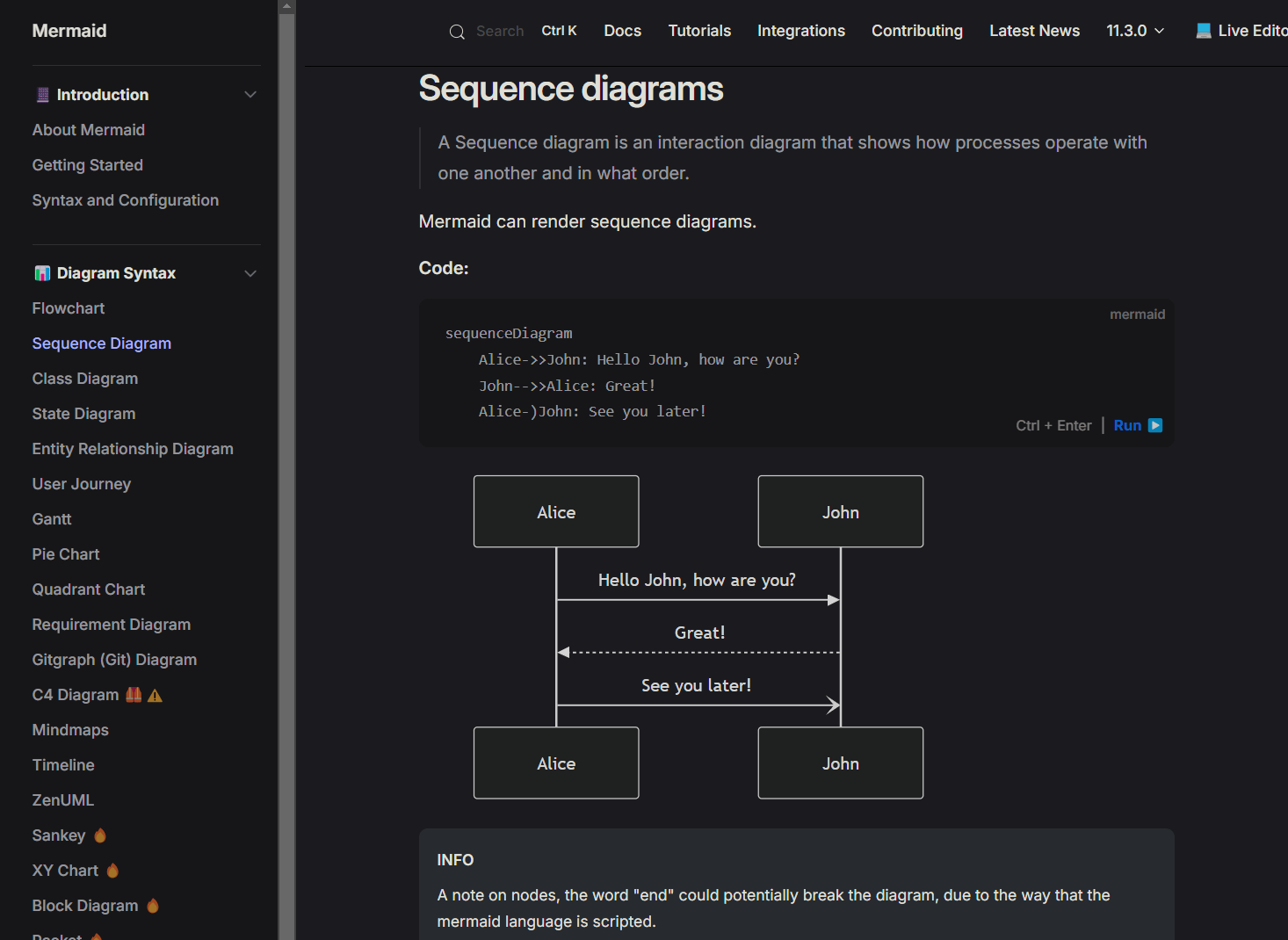
Éditeurs en ligne
Pour faciliter les opérations, des éditeurs en ligne très bien conçus vous permettent de partir de modèles et de vous adapter progressivement à la syntaxe avec un aperçu du résultat.
- Mermaid Live Editor - gratuit, très souple, affichage plein écran et quelques options de mise en forme.
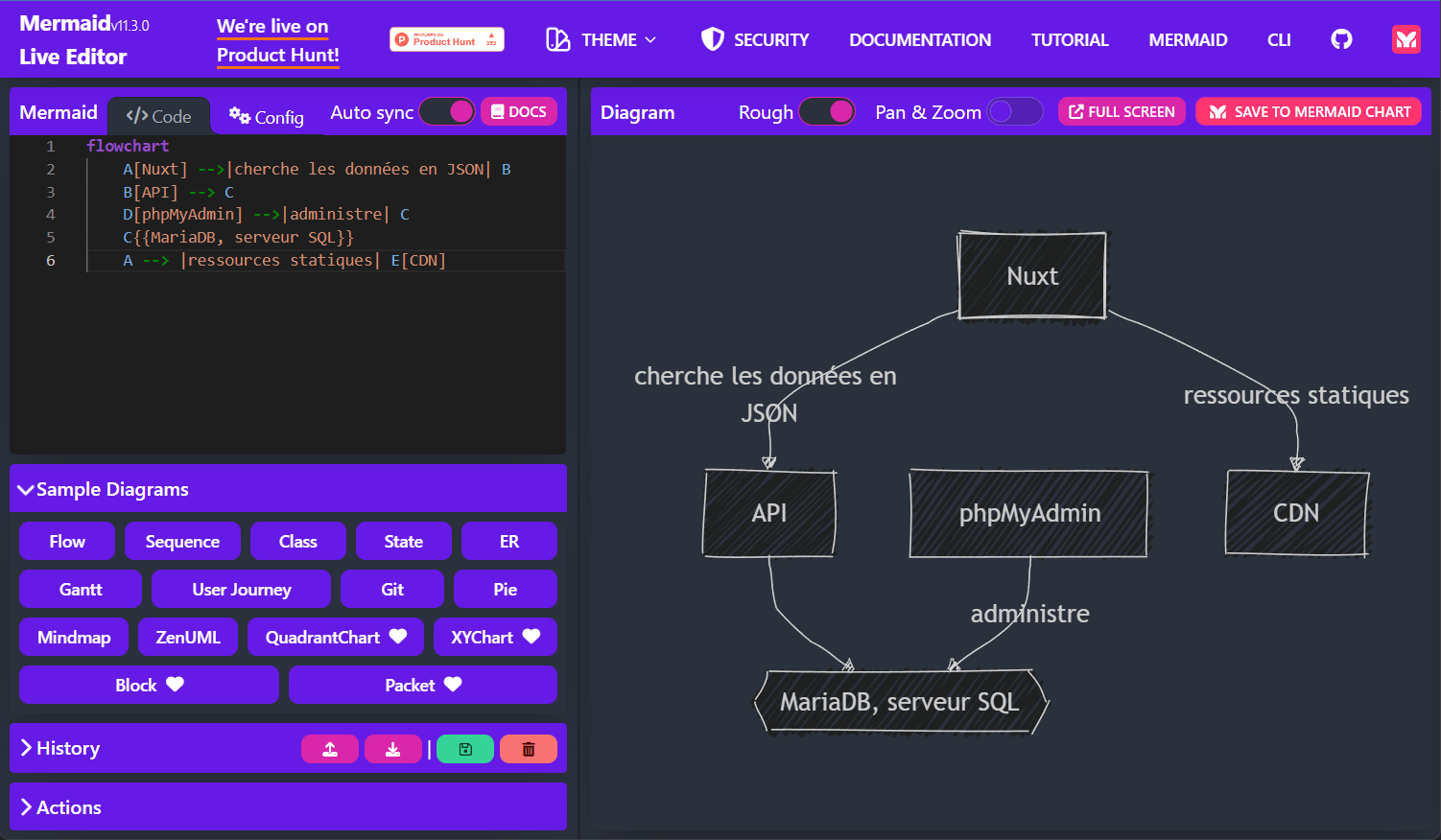
Il permet aussi le partage par URL c'est-à-dire d'encoder le contenu dans l'adresse et de la diffuser pour retrouver le schéma d'origine, par exemple pour le résultat ci-dessus :
https://mermaid.live/edit#pako:eNo1T8tOxDAM_BUr5-4P9IDUBwcQW0A9tnuwErON2CTFSYBV0w_iO_gxslvWkqXxaGZsL0I6RaIUbyf3JSfkMFrIVQ1d_A4H2O3ukpyIc8OJPChn7e9PBmThsX_uEtSboR6ql4erHpqNaYd5mvfnShlttyC8QO0DU7qJmmXZI2ts6wI88SdFhv71aV3_z7gGJibvXWSZ9_qAQX9E8gnuh6btDiAKYYgNapXfWC6-UYSJDI2izFAhv49itGvWYQyuP1spysCRCsEuHqfbEGeFgVqNR0azkesfwYJfFw
- Mermaidchart - freemium
- Mermaid ASCII - projet open-source
Génère des rendus en ASCII art (ou dans un Terminal).
$ cat test.mermaid
graph LR
A --> B & C
B --> C & D
D --> C
$ mermaid-ascii --file test.mermaid
+---+ +---+ +---+
| | | | | |
| A |---->| B |---->| D |
| | | | | |
+---+ +---+ +---+
| | |
| | |
| | |
| | |
| v |
| +---+ |
| | | |
------->| C |<-------
| |
+---+
Pimp my mermaid
Mermaid est un projet open source, ce qui signifie qu'il est possible de l'étendre ou de le modifier pour des besoins spécifiques si nécessaire.
Enfin, on peut avoir accès à des thèmes de couleur
- par défaut - pour tous les diagrammes.
- neutre - idéal pour les documents en noir et blanc qui seront imprimés.
- sombre - convient bien aux éléments de couleur sombre ou au mode sombre.
- forêt - avec des nuances de vert.
- base - le seul thème qui peut être modifié
Bref, c'est rudement pratique, on le prend en main facilement et vous serez fiers de pouvoir documenter vos projets, wiki, issues avec de beaux schémas compréhensibles.
Tout le monde connaît désormamis le terme "URL" pour désigner une adresse sur le web. Bien que certains navigateurs tentent de la simplifier au maximum dans la barre de navigation (et peut être un jour de l'invisibiliser), elle revêt une importance capitale pour savoir où on est, et où on va.
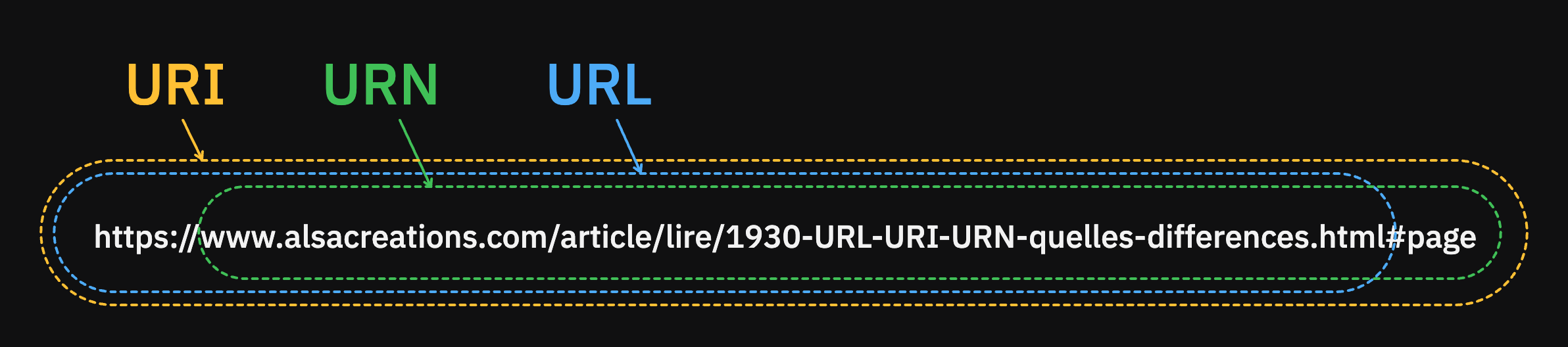
Première chose à savoir : URL et URN sont des sous-types d'URI.
URI
L'URI (Uniform Resource Identifier) est le terme le plus général qui englobe à la fois URL et URN : c'est une chaîne de caractères qui identifie de manière unique une ressource. Cela peut se faire par l'emplacement de la ressource, son nom, ou les deux.
Un chemin de fichier local pourrait donner une bonne idée d'URI :
file:///C:/Documents/Dossier/image.png
Dans cet exemple :
- Le schéma est
file(on comprend donc que la ressource est locale). - Le séparateur
://(que l'on retrouve également dans les URLs) distingue le schéma de l'adresse, c'est une convention admise partout, mais ici nous sommes dans un cas particulier : en général les//précèdent un nom d'hôte, nom de domaine, adresse IP or ici nous sommes en local donc il n'y en a pas, c'est pourquoi on peut voir directement trois slash à la suite///. - L'adresse (locale) vers la ressource est donc
/C:/Users/Utilisateur/Documents/monfichier.txtc'est-à-dire à peu près un chemin que vous pouvez écrire de manière traditionnelle sur un système d'exploitation Windows.
URN
L'URN (Uniform Resource Name) est un type d'URI, identifiant une ressource par son nom dans un espace de noms particulier. Ici on ne spécifie pas comment accéder à la ressource (pas de protocole par exemple) mais seulement son identité, qui en théorie devrait être unique et persistante, indépendemment d'un endroit de stockage (contrairement à une URL).
Par exemple un numéro d'ISBN (International Standard Book Number) qui identifie de manière unique un livre peut être écrite sous forme d'URN.
urn:isbn:978-2-212-67683-9
On peut également écrire un numéro de téléphone.
urn:tel:+33123456789
Ou encore un UUID (Universally Unique IDentifier) qui est très utilisé en développement, ou pour donner des identifiants à des ressources matérielles.
urn:uuid:123e4567-e89b-12d3-a456-426614174000
Dans ces exemples
- Les séparateurs sont des
: - On préfixe par
urn - On ajoute le protocole/schéma.
- On termine par l'identifiant de la ressource.
URL
L'URL quant à elle sert évidemment d'adresse pour chaque page web, fichier quelconque sur Internet et plus particulièrement sur le web même si ce n'est pas le seul protocole qui l'exploite.
Par exemple on peut écrire une URL pour une adresse FTP (File Transfer Protocol) - qui d'ailleurs à une époque pouvait être reconnue et exploitée par la plupart des navigateurs :
ftp://login:password@ftp.schnapsgpt.com:21/dossier/image.png
On reconnaît les mêmes principes que précédemment avec le schéma (protocole), les sépararateurs divers :, @, / et l'ajout ici d'informations d'identifications pour accéder à la ressource login:password ainsi que le port 21.
Dans le cas d'une URL pour le web, nous retrouverons le protocole http ou https (sécurisé d'une certaine façon).
https://www.alsacreations.com/article/lire/1930-URL-URI-URN-quelles-differences.html
Ces adresses apportent des avantages :
- Elles reflètent souvent la structure hiérarchique d'un site web pour comprendre l'organisation du contenu (si on a bien fait le travail de structuration).
- Elles permettent le partage par lien, universel entre des milliers d'applications, même sur mobile.
- Elles permettent d'identifier la source d'une information par le nom de domaine... sauf si des personnes fourbes réservent un nom avec des caractères internationaux/Unicode très similaires, soit une attaque homographe pour faire pointer vers un autre site non moins fourbe.
En bonus, de belles URLs sont exploitées par les robots des moteurs de recherche (coucou Googlebot) pour mieux comprendre et indexer les pages web: bien pensées elles peuvent améliorer le référencement d'un site.
D'où vient l'URL ?
L'invention de l'URL est attribuée à Tim Berners-Lee (encore lui !) l'inventeur de bien des composants essentiels du web : HTML, le premier navigateur, le premier serveur (pour lui répondre), et le protocole HTTP. Rien que ça.
Cet adressage date donc des années 1990 lorsque Tim développait ses projets au CERN à Genève. Il souhaitait pouvoir fournir un adressage des documents et autres ressources sur le réseau informatique qu'il était en train de créer. Au fur et à mesure, le concept a été amélioré par l'IETF (Internet Engineering Task Force).
En savoir bien plus
Écoutez l'épisode Disséquons une URL, première partie de l'excellent Carré, Petit, Utile : Le programme radio des gens du numérique.
L'URL est un standard décrit par la RFC 1738, précisée dans le cas des liens mailto par la RFC 2368... complétée par la RFC 2396 sur les URI, puis par la RFC 3986 l'élargissant encore plus aux URI, ainsi que la RFC 8089 sur les noms locaux de fichiers, et ainsi de suite.
Nous n'avons pas fini d'entendre parler de les LLM (grands modèles de langages) et de l'Intelligence Artificielle. Outre les sytèmes en ligne (souvent payants) il est possible d'interroger un modèle local (gratuitement) par l'intermédiaire d'un peu de JavaScript.
Pour ceci nous utiliserons :
- Ollama qui permet de télécharger des modèles au choix
- Un des modèles proposés, par exemple llama de Meta
- La bibliothèque JavaScript Ollama (package npm)
Ollama
Ollama est une application disponible pour Linux, macOS, Windows qui sert d'interface de gestion de LLM. Voyons la comme une sorte de Docker qui ira piocher dans un catalogue d'images disponibles en ligne, faciles à télécharger et à exécuter en une seule instruction ou presque en précisant bien le nom du modèle souhaité.
Les commandes essentielles après avoir téléchargé et installé Ollama :
ollama listliste les modèles déjà téléchargésollama pull <modèle>télécharge un nouveau LLMollama run <modèle>exécuteollama stop <modèle>met fin à l'exécutionollama rm <modèle>supprime
Pour l'occasion, nous utiliserons llama 3.2
ollama pull llama3.2
Pour préciser une autre version du modèle avec nombre de paramètres (comprenez complexité et poids) différent, on pourra par exemple indiquer ollama pull llama3.2:1b pour 1B soit un milliard de paramètres.
Jusque-là si tout va bien, nous pouvons d'ores et déjà discuter en mode texte brut par un ollama run llama3.2.
Package JavaScript Ollama
Cette bibliothèque nous permet d'aller interroger Ollama installé localement en définissant le modèle, le message à lui envoyer et en traitant la réponse. De manière très basique on peut se servir de console.log mais ce n'est pas très intéressant car bloquant jusqu'à obtenir la totalité de la réponse ; la promptitude du modèle dépendra aussi de la puissance de votre machine et de votre mémoire vive disponible.
À l'aide d'un environnement Node.js (déjà installé n'est-ce pas ?), nous pouvons poursuivre.
Créer un dossier quelconque ð pour notre projet.
Installer la dépendnace avec
npm install --save ollama(ou avec pnpm)
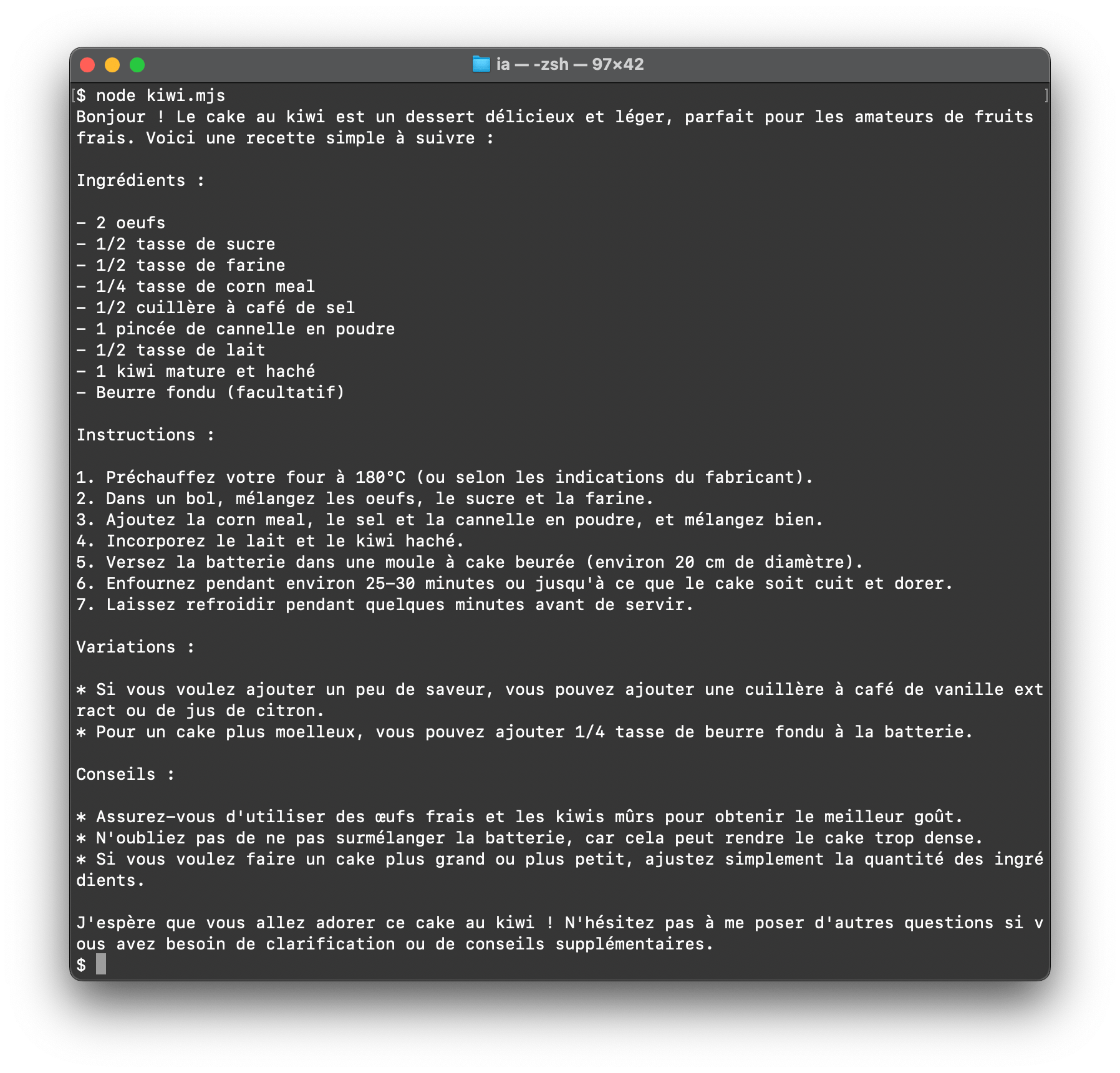
- Écrire un petit script
kiwi.mjspour importerollamaet appelerchat()afin de lancer la discussion
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2',
messages: [{ role: 'user', content: 'Quelle est la recette du cake au kiwi ?' }],
})
// â ï¸ Ceci peut prendre beaucoup de temps car on attend la réponse complète
console.log(response.message.content)
Il suffira de l'exécuter en ligne de commande avec node kiwi.mjs.
Pour streamer la réponse, c'est-à-dire la restituer au fur et à mesure de l'ajout de mots par le LLM, on peut se servir de l'alternative en activant l'option stream.
import ollama from 'ollama'
const message = { role: 'user', content: 'Quelle est la recette du cake au kiwi ?' }
const response = await ollama.chat({ model: 'llama3.2', messages: [message], stream: true })
for await (const part of response) {
process.stdout.write(part.message.content)
}
Un bon nombre d'autres paramètres et méthodes existent dans cette interface, il suffira de consulter la documentation pour les découvrir.
Et en application web ?
C'est possible ! Une page interrogera le modèle via ollama :
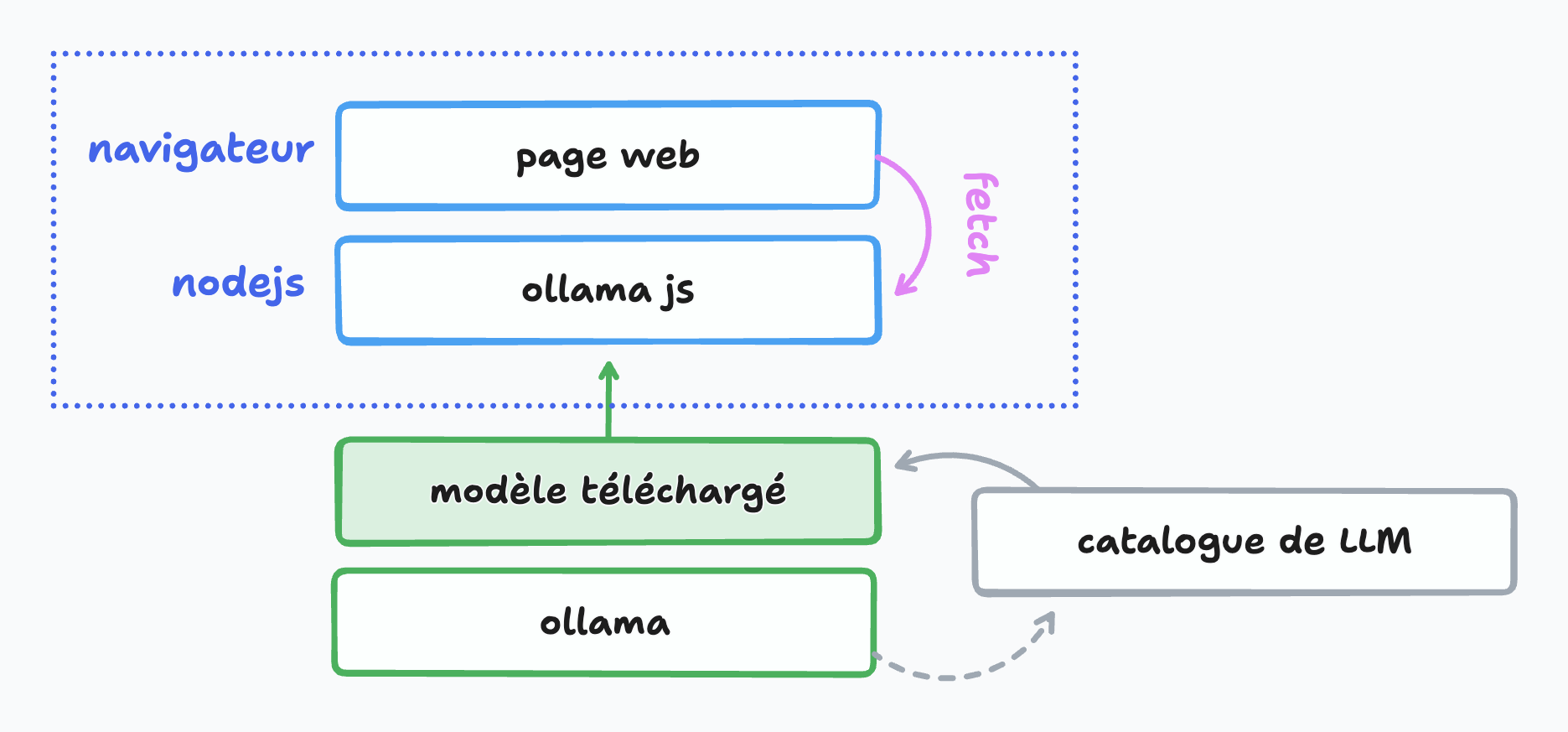
Pour transformer le tout en une petite application web utilisable dans le navigateur...
- Nous ajoutons
express
npm install --save express
Ce qui va permettre de construire un couple client/serveur minimaliste avec deux fichiers :
- server.mjs, qui sera à l'écoute des messages
- public/index.html, qui contiendra un formulaire et affichera le résultat
Les explications sont fournies par des commentaires dans le code source suivant, à vous de jouer en vous l'appropriant.
- Fichier
server.mjs
import express from 'express';
import ollama from 'ollama';
const app = express(); // Instance d'Express
const port = 3000; // Port à l'écoute
app.use(express.json());
// On sert le dossier public en statique, dans lequel on place notre page index.html
app.use(express.static('public'));
// On accepte les requêtes POST vers /chat
app.post('/chat', async (req, res) => {
// Notre message sera envoyé dans le corps de la requête (body)
const message = { role: 'user', content: req.body.content };
// La réponse provenant du LLM est une promesse
const response = await ollama.chat({ model: 'llama3.2', messages: [message], stream: true });
// La réponse envoyée à la page web dispose d'en-têtes HTTP
// ... permettant de faire persister la connexion
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive'
});
// Pour toute portion de réponse reçue, on la stream
for await (const part of response) {
res.write(`data: ${JSON.stringify(part.message)}\n\n`);
}
res.end();
});
// On écoute sur le port configuré
app.listen(port, () => {
console.log(`Serveur en écoute : http://localhost:${port}`);
});
- Page
public/index.htmlcorrespondante :
<!doctype html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>KiwIA</title>
<style>
/* à personnaliser selon vos envies */
body { font-family: system-ui; background: #222; color: #fff; padding: 2rem; }
#chat, [type=submit] { padding: 1rem; border-radius: 0.5rem; border: 1px solid #ccc; margin: 1rem 0; background: inherit; color: inherit; }
#chat { min-width: 20rem; font-size: inherit; }
#reponse { text-align: left; line-height: 2; }
</style>
</head>
<body>
<h1>Chat KiwIA ð¥</h1>
<form>
<input type="text" id="chat" placeholder="Votre message...">
<button type="submit">Envoyer</button>
</form>
<div id="reponse"></div>
<script>
const form = document.querySelector('form');
const input = document.querySelector('#chat');
const resultat = document.querySelector('#reponse');
// À la validation du formulaire
form.addEventListener('submit', async (e) => {
e.preventDefault();
// On récupère le contenu du message
const content = input.value.trim();
if (!content) return; // Si c'est vide on arrête là
// Petit message d'attente
resultat.textContent = 'Un instant et je suis à vous...';
// On vide le champ d'entrée
input.value = '';
try {
// Requête asynchrone en POST vers /chat
const response = await fetch('/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
// Corps de la requête en JSON
body: JSON.stringify({ content }),
});
resultat.textContent = '';
// On instancie une interface ReadableStream
const reader = response.body.getReader();
const decoder = new TextDecoder();
// Tant qu'on a du contenu...
while (true) {
const { done, value } = await reader.read(); // On lit
if (done) break;
const lines = decoder.decode(value).split('\n');
// On itère sur la réponse reçue pour alimenter le résultat
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
resultat.textContent += data.content;
}
}
}
} catch (error) {
console.error('Error:', error);
resultat.textContent = 'Une erreur est survenue.';
}
});
</script>
</body>
</html>
- On lance le tout grâce à
node server.mjset on consulte l'adresse indiquée dans le navigateur pour atteindre la page HTML qui affiche le formulaire.
On peut perfectionner le rendu en mettant en page le message renvoyé sous forme de markdown (mais cela dépend du modèle interrogé) plutôt que de l'afficher en texte brut.
Perspectives
On peut voir que construire une application web sollicitant un LLM est tout à fait envisageable avec les technologies d'aujourd'hui et les standards déjà en place (HTML/CSS, JavaScript, fetch, Streams API, etc). À partir de là tout est possible pour imaginer élaborer des interfaces qui vont dialoguer en texte clair ou par d'autres moyens plus subtiles, et réagir en conséquence. Vous pouvez aussi briefer votre LLM en amont et lui donner des instructions ou un contexte de réponse, voire en construire un nouveau (avec l'instruction FROM de Ollama).
Pour pousser l'horizon encore plus loin, faire tourner des LLM dans le navigateur lui-même est possible grâce à WebGPU (voir une démo ici : Qwen-2.5 on WebGPU sur Huggingface) avec une performance tout à fait honorable.
Les concepteurs de navigateurs préparent des interfaces aisées d'accès en JavaScript pour interroger un modèle local, tels que Google avec l'IA Gemini intégrée dans Chrome. Nous n'avons pas fini d'en entendre parler.
Retrouvez l'intégralité de ce tutoriel en ligne sur Alsacreations.com